유니티의 직렬화는 어떤 구조로 구성되어있을까?
크게 GUID와 fileID로 파일과 객체를 구분하여 저장한다.
GUID
GUID는 파일 단위의 유니크한 식별자이다. 때문에 에셋 파일에만 부여되는 ID값이다. (GameObject, Component 등은 없음)

헷갈릴 수 있는 사실은 Scene과 Prefab도 Asset으로 관리되기에 GUID가 있다는 점이다.
특히 Prefab은 GameObject랑 혼동될 수 있으니 주의해야한다.
GameObject는 Scene파일 내에서 관리하고, Prefab은 별도의 에셋이다.
fileID
GUID가 부여된 Asset파일 안에 있는 오브젝트를 식별하기 위한 ID값이다. (Scene안의 GameObject, Component와 Fbx안의 Mesh, Metarial등이 해당한다). 따라서 서브에셋이 없는 에셋(예를 들어 텍스쳐, 스크립트 등)은 fileID가 존재하지 않는다.
fileID는 에셋 단위에 식별하는 값이므로 겹칠 수 있다.
실제로 Scene파일의 Transform 계층 정보나, MeshFilter 컴포넌트의 멤버 직렬화 구조가 이런 방식으로 되어있다.

이 MeshFilter의 직렬화 구조는 어떤 파일(GUID)의 어떤 메쉬(fileID)를 사용하겠다. 라는 뜻이다.
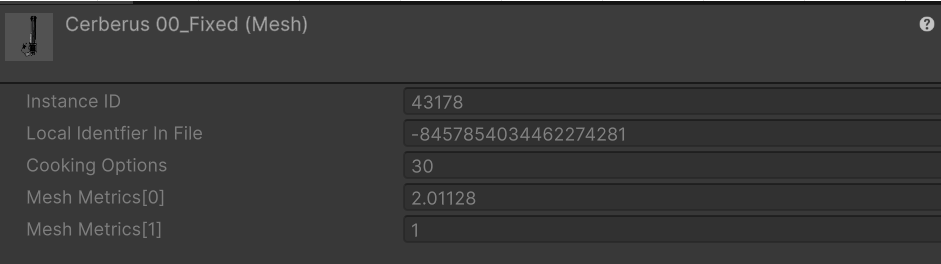
아래 사진은 순서대로 해당 모델의 fbx에셋 GUID, 그리고 모델 해당 메쉬의 fileID이다.


type
사실 별로 알 필요는 없다. 하지만 굳이 적어보자면, 해당 에셋이 무슨 타입인지 지정하는 것이다.
에디터를 쓰는 사람 입장에선 이럴 것이다.
Transform에 들어간 정보면 어차피 Transform일테고, MeshFilter에 들어간 정보면 당연히 Mesh일텐데 뭐하러 type이 있는가?
정답은 아무도 모르겠지만 내 생각은 이렇다. 우리는 사람이라 무슨 타입인지 당연히 특정할 수 있지만, 컴퓨터는 이게 무슨 타입인지 모른다.
무슨 말이냐면, 해당 파일(GUID)의 객체(fileID)에 접근했으나, 해당 객체가 무슨 타입(class)인지 알아야 해당 멤버를 사용할 수 있을텐데 컴퓨터입장에선 모르므로, 유니티 내부에서 type이라는 정수값을 통해 타입캐스팅을 해주는 것이 아닌가 하는 추측이다. 참고로 정확한 정보를 찾지 못해 어떤 정수가 어떤 타입을 의미하는지는 모르겠다.
보면 Script도, MeshFilter도 type값이 3이다. 컴포넌트 자체가 3을 의미할 가능성이 높다.
InstanceID
사실 직렬화랑 관계는 없지만 헷갈릴 가능성이 있어서 번외로 적었다.
InstanceID는 직렬화 시에는 저장하지 않고 메모리에 올라가는 동적 객체들을 식별하기 위해 쓰는 ID값이다.
실제로 프로그램을 껏다 키면 InstanceID가 바뀌어 있는 것을 확인할 수 있다.
초기 세팅을 위한 직렬화할때는 guid와 fileID를 사용하고, 그 후 런타임엔 InstanceID를 사용하는 듯 하다.
InstanceID는 생성규칙이 있는데, 파일에서 로드된 객체는 양수가 부여되고 런타임에 만들어진 개체는 음수가 부여된다는 것이다.
처음엔 이걸 굳이 왜쓰지? C++의 포인터랑 다른게 뭐지 했는데, 약간 포인터의 단점을 보완한 것 같다.
나의 추측은 이렇다.
1. 객체가 이동 시, 주소 값이 바뀐다. 이 경우에 해당 객체를 가리키던 모든 포인터들이 댕글링 상태가 되어 위험한데, InstanceID로 식별할 경우 객체가 이동해도 매핑테이블의 정보만 바꿔주면 댕글링포인터를 접근할 가능성이 줄어든다.
2. 실제로 댕글링포인터 접근을 막아준다. 객체가 삭제시 매핑테이블에 자신의 InstanceID값에 있는 데이터를 NULL로 바꿔 놓으면 다음에 접근할 때, 객체가 삭제되어있는지 알 수 있기때문에 댕글링포인터 접근 가능성이 거의 사라진다고 보면 된다.
Script의 Serialize
스크립트를 작성해본 사람들은 SerializeField가 뭔지 알것이다.
SerializeField는 해당 변수를 직렬화와 역직렬화 지원을 하겠다는 뜻이다. 그런데 어떤 구조로 저장할까?
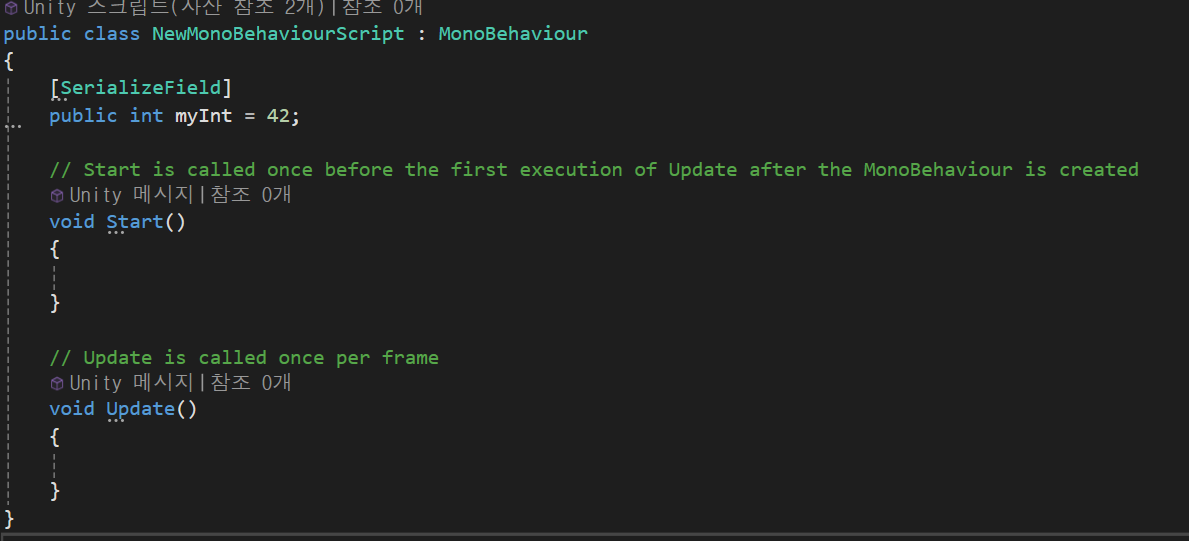
이러한 스크립트가 있다. 말 그대로 MyInt를 직렬화하겠다는 내용이다.
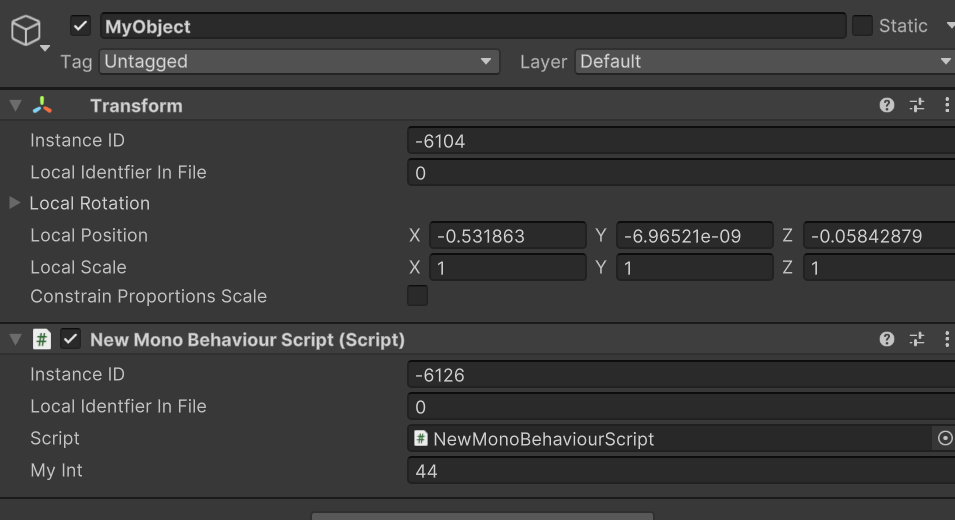
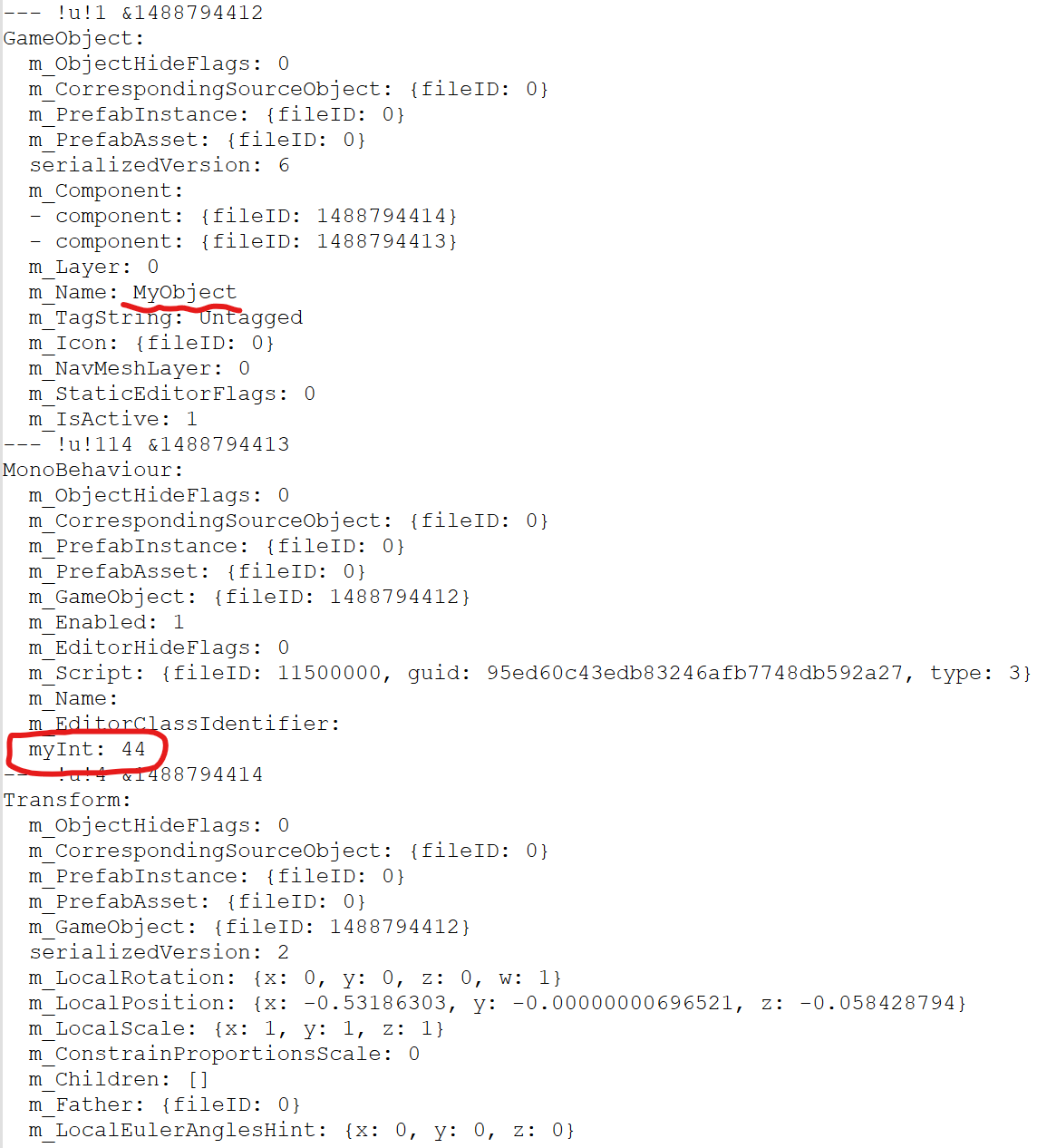
이걸 GameObject에 부착시키고, Scene파일에서 해당 GameObject의 직렬화 정보를 보면 아래와 같다.
여기서 MyInt를 없애고 MyFloat라는 변수를 추가해 보았다.
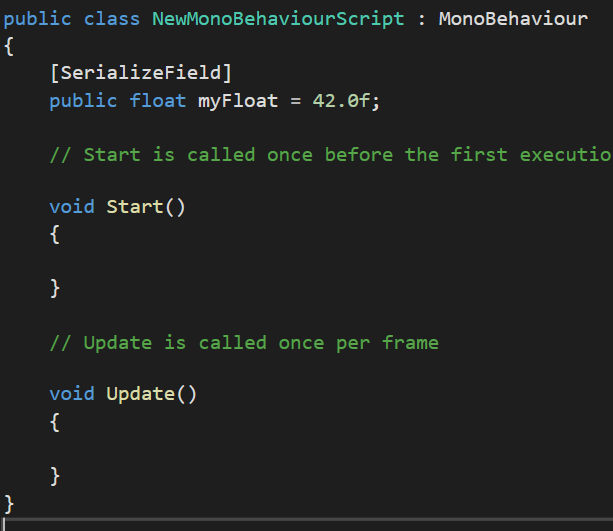
어떻게 변할까?
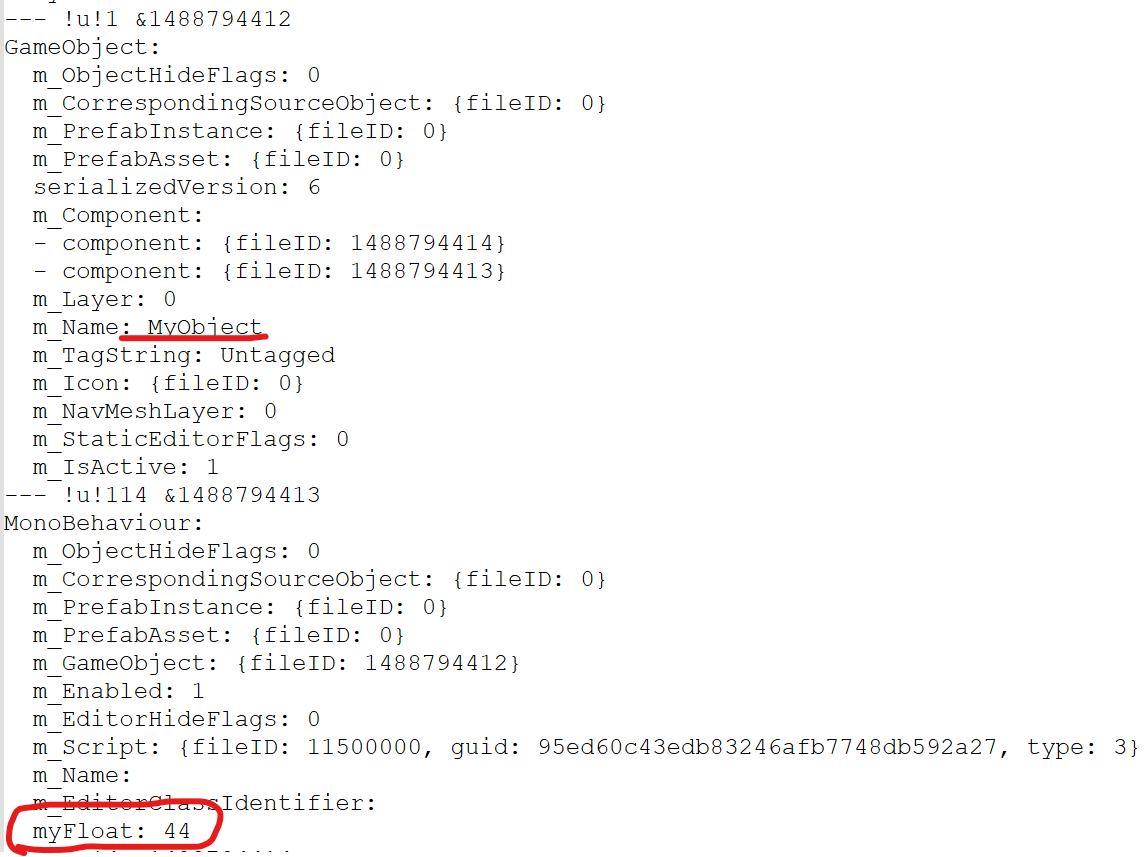
그냥 단순하게 myInt가 삭제되고 myFloat가 추가된다.
myInt가 사라진 걸 아는거보니까, 저장 시에 아예 처음부터 다 덮어씌우나보다.
근데 이상한건 MonoBehaviour로 저장이 되어있는데 스크립트들을 어떻게 구분한걸까?
그건 아까도 말했듯, GUID로 구분한다.
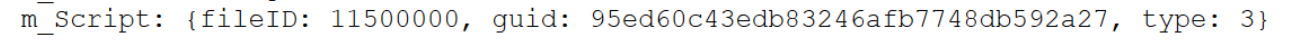
마지막으로, 유용한 글이 있어 남긴다.
이걸 보고 포스팅했으면 더 확실했을 것 같은데 귀찮아서 패스.
[번역] 에셋과 오브젝트, 그리고 직렬화 :: 코드쿡