사진출처: IPC
IPC가 뭘까?
예전에 프로세스에 관해 포스팅을 했었을 때, 각 프로세스는 독립적인 주소공간을 가진다고 했었습니다. 즉 프로세스끼리는 서로의 메모리를 공유할 수 없다는 뜻인데요. 진짜일까요?
당연하게도 프로세스는 서로 데이터를 공유할 수 있는 방법이 있습니다. 그걸 바로 IPC통신이라고 하는데요.
커널은 IPC자원(커널 객체)와 IPC메서드 등을 관리 및 제공하며, 개발자는 운영 체제가 제공하는 IPC자원과 API, 인터페이스를 사용하여 프로세스간 통신을 구현할 수 있습니다.
IPC의 종류
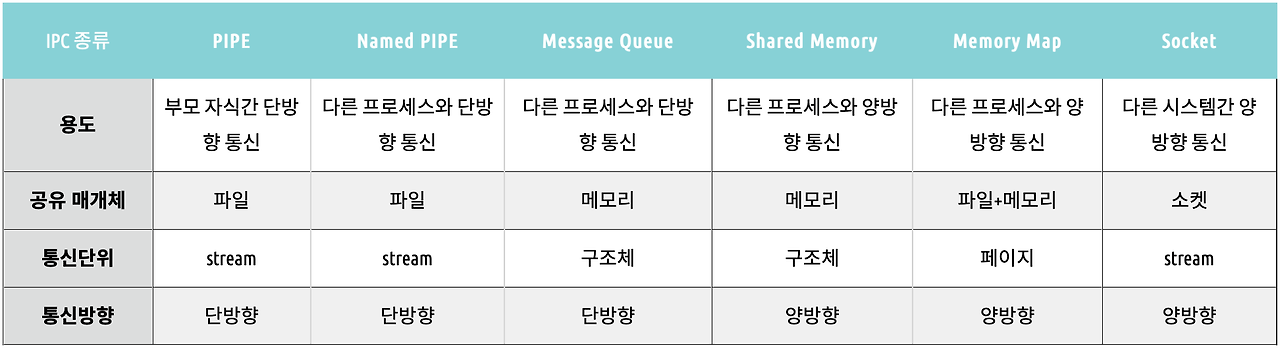
IPC통신에도 많은 종류가 있으며, 상황에 따라 맞는 방법을 선택해 사용하는 것이 중요합니다.
익명 파이프(Anonymous Pipe)

특징
- 부모-자식 프로세스 간의 단방향 통신을 위해 사용합니다.
- 데이터를 FIFO(First In, First Out) 방식으로 처리합니다.
장점
- 운영 체제에서 기본적으로 API및 인터페이스를 제공하여 사용이 쉽습니다.
- 부모-자식 프로세스 간의 파이프 연결이 다른 IPC설계보다 쉽습니다.
단점
- 기본적으로 단방향 통신이므로 프로세스가 읽기, 쓰기를 둘다 하려면 두 개의 파이프를 만들어야 합니다.
- 각 프로세스가 부모-자식 관계가 아니면 사용이 불가능합니다.
사용법
CreatePipe 함수(namedpipeapi.h) - Win32 apps | Microsoft Learn
CreatePipe 함수(namedpipeapi.h) - Win32 apps
익명 파이프를 만들고 파이프의 읽기 및 쓰기 끝에 핸들을 반환합니다.
learn.microsoft.com
익명 파이프 생성 예시
#include <iostream>
#include <Windows.h>
int main()
{
HANDLE hRead, hWrite;
// 이 예제는 부모-자식 프로세스에 대한 구분이 없으므로 실제로 사용할 땐, CreateProcess로 부모 프로세스가 자식 프로세스를 생성해야한다.
// 익명 파이프 생성
if (CreatePipe(&hRead, &hWrite, NULL, 0))
{
std::cout << "익명 파이프 생성 성공" << '\n';
}
else
{
std::cerr << "익명 파이프 생성 실패" << '\n';
return 1;
}
// 쓰기 쓰레드: 데이터를 파이프에 쓰기
const char* data = "Hello, Anonymous Pipe!";
DWORD bytesWritten;
if (WriteFile(hWrite, data, strlen(data) + 1, &bytesWritten, NULL))
{
std::cout << "파이프에 데이터 쓰기 성공: " << bytesWritten << " 바이트" << '\n';
}
else
{
std::cerr << "파이프 쓰기 실패" << '\n';
}
// 읽기 쓰레드: 데이터를 파이프에서 읽기
char buffer[128] = { 0 };
DWORD bytesRead;
if (ReadFile(hRead, buffer, sizeof(buffer) - 1, &bytesRead, NULL))
{
std::cout << "파이프에서 데이터 읽기 성공: " << buffer << '\n';
}
else
{
std::cerr << "파이프 읽기 실패" << '\n';
}
// 커널 객체 반납
CloseHandle(hRead);
CloseHandle(hWrite);
return 0;
}이름 있는 파이프(Named Pipe)

특징
- 부모-자식 프로세스가 아닌 프로세스와의 단방향 통신을위해 사용합니다.
- 데이터를 FIFO(First In, First Out) 방식으로 처리합니다.
- 이름을 통해 특정 파이프를 식별합니다.
- 여러 프로세스가 동일한 파이프에 접근 가능합니다.
- 기본적으로 단방향 통신이지만, 운영체제에 따라 양방향이 가능합니다.
장점
- 운영 체제에서 기본적으로 API및 인터페이스를 제공하여 사용이 쉽습니다.
- 부모-자식 프로세스 관계에 제한되지 않습니다.
단점
- 기본적으로 단방향 통신이므로 프로세스가 읽기, 쓰기를 둘다 하려면 두 개의 파이프를 만들어야 합니다.
- 파이프의 설정과 관리가 익명 파이프보다 복잡합니다.
사용법
CreateNamedPipeA 함수(winbase.h) - Win32 apps | Microsoft Learn
CreateNamedPipeA 함수(winbase.h) - Win32 apps
ANSI(CreateNamedPipeA) 함수(winbase.h)는 명명된 파이프의 인스턴스를 만들고 후속 파이프 작업에 대한 핸들을 반환합니다.
learn.microsoft.com
네임드 파이프 생성 예시 (읽기, 쓰기는 없음)
#include "pch.h"
#include <iostream>
int main()
{
return 0;
HANDLE hPipe = CreateNamedPipe(
L"\\.\pipe\MyPipe", // 파이프 이름(\\.\pipe\의 뒤에 이름)
PIPE_ACCESS_DUPLEX, // 양방향 통신
PIPE_TYPE_BYTE | PIPE_WAIT, // 바이트 스트림과 동기식 통신
1, // 인스턴스 개수
512, 512, // 출력/입력 버퍼 크기
0, // 기본 타임아웃
NULL // 보안 속성
);
CloseHandle(hPipe);
return 0;
}메시지 큐 (Message Queue)

특징
- 커널이 관리하는 메시지 큐를 통해 데이터를 주고받습니다.
- 데이터를 FIFO(First In, First Out) 방식으로 처리합니다.
- 송신과 수신이 독립적으로 동작하는 비동기성으로 동작합니다.
- 운영체제가 메시지 큐의 생성 및 관리를 담당합니다.
장점
- 운영 체제에서 기본적으로 API및 인터페이스를 제공하여 사용이 쉽습니다.
- 비동기적 데이터 통신방식이므로 송신자와 수신자가 동시에 동작할 필요 없음.
단점
- 운영체제마다 API가 다르므로 주의해야 합니다.
- 메시지 타입과 큐 ID등의 메세지를 명확히 전송해야 합니다.
사용법
C-C++ 코드 예제: 큐 만들기 | 마이크로소프트 런
C-C++ Code Example: Creating a Queue
C-C++ Code Example: Creating a Queue Article 10/19/2016 In this article --> Applies To: Windows 10, Windows 7, Windows 8, Windows 8.1, Windows Server 2008, Windows Server 2008 R2, Windows Server 2012, Windows Server 2012 R2, Windows Server Technical Previe
learn.microsoft.com
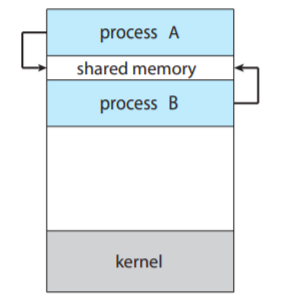
공유 메모리 (Shared Memory)
특징
- 한 메모리 영역을 여러 프로세스가 공유하여 사용하는 방식입니다.
- 이는 서로의 메모리 주소공간을 공유한다는 것이 아니라, OS가 공유가능한 메모리 공간을 할당하여 여러 프로세스에게 접근 가능하게 해줍니다.
장점
- 프로세스가 데이터를 메모리에 복사하는 것이 아닌, 직접 쓰고 읽으므로 속도가 빠릅니다.
- 여러 프로세스가 동일한 데이터를 읽기, 쓰기가 가능합니다.
- 다른 IPC에 비해 비교적 큰 데이터를 처리하기가 간편합니다.
단점
- 데이터의 동기화 문제에 주의해야 합니다.
- 메모리에 직접 접근하므로 보안에 취약할 수 있습니다.
- 할당한 메모리를 해제하지 않으면 메모리 누수가 발생할 수 있습니다.
사용법
명명된 공유 메모리 만들기 - Win32 apps | Microsoft Learn
명명된 공유 메모리 만들기 - Win32 apps
데이터를 공유하기 위해 여러 프로세스는 시스템 페이징 파일이 저장하는 메모리 매핑 파일을 사용할 수 있습니다.
learn.microsoft.com
쓰기
#include <windows.h>
#include <iostream>
// 쓰는 프로세스
int main()
{
// 공유 메모리 생성
HANDLE hMapFile = CreateFileMapping(
INVALID_HANDLE_VALUE, // 물리적 파일이 아닌 메모리 사용
nullptr, // 기본 보안 속성
PAGE_READWRITE, // 읽기/쓰기 가능
0, // 고위 메모리 크기 (사용 안 함)
256, // 공유 메모리 크기 (256 바이트)
L"SharedMemoryExample"); // 공유 메모리 이름
// 공유 메모리 매핑
LPVOID pBuf = MapViewOfFile(
hMapFile, // 메모리 매핑 핸들
FILE_MAP_ALL_ACCESS, // 읽기/쓰기 액세스
0, 0, 0); // 전체 영역 매핑
// 데이터 쓰기
const char* message = "Hello!";
CopyMemory(pBuf, message, strlen(message) + 1);
Sleep(5000);
UnmapViewOfFile(pBuf);
CloseHandle(hMapFile);
return 0;
}읽기
#include <windows.h>
#include <iostream>
// 읽는 프로세스
int main()
{
Sleep(1000);
// 공유 메모리 열기
HANDLE hMapFile = OpenFileMapping(
FILE_MAP_ALL_ACCESS, // 읽기/쓰기 액세스
FALSE, // 자식 프로세스 상속 여부 (아니오)
L"SharedMemoryExample"); // 공유 메모리 이름 (생성 시와 동일해야 함)
// 공유 메모리 매핑
LPVOID pBuf = MapViewOfFile(
hMapFile, // 메모리 매핑 핸들
FILE_MAP_ALL_ACCESS, // 읽기/쓰기 액세스
0, 0, 0);
// 데이터 읽기
std::cout << "공유 메모리에서 데이터를 읽었습니다: " << static_cast<char*>(pBuf) << std::endl;
UnmapViewOfFile(pBuf);
CloseHandle(hMapFile);
}소켓 (Socket)
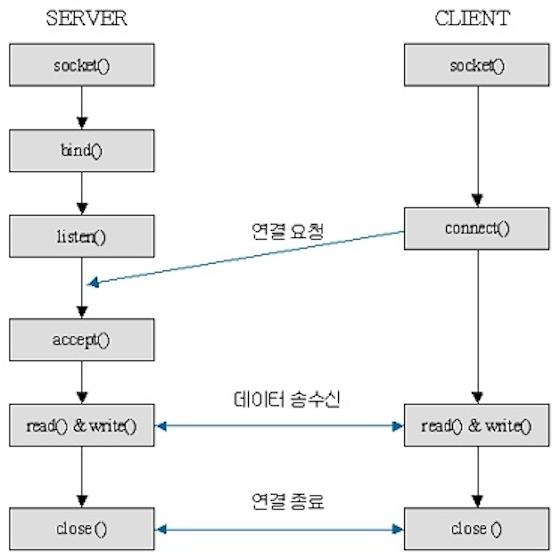
특징
- 네트워크 인터페이스를 통해 두 프로세스가 데이터를 주고받는 방식입니다.
- 데이터를 양방향으로 주고받을 수 있습니다.
- TCP(연결 지향)방식과 UDP(비연결 지향)방식이 있습니다.
장점
- 같은 시스템 내에서의 통신 뿐만이 아니라, 네트워크를 통한 다른 컴퓨터와의 통신이 가능합니다.
- 대상이 서로 다른 운영체제여도 통신이 가능합니다.
- 실시간으로 데이터 전송이 가능합니다.
단점
- 소켓 통신은 패킷의 처리, 예외 처리 등에 대한 구현이 필요하므로 복잡합니다.
- 네트워크 자원을 사용하기 때문에 연결 수가 많아질수록 리소스 사용이 급격히 많아집니다.
- 데이터를 암호화하지 않으면 보안에 취약할 수 있습니다.
사용법
socket 함수(winsock2.h) - Win32 apps | Microsoft Learn
socket 함수(winsock2.h) - Win32 apps
소켓 함수는 특정 전송 서비스 공급자에 바인딩된 소켓을 만듭니다.
learn.microsoft.com
소켓 서버/클라이언트 예시 코드
*서버
#include<iostream>
#include<string>
#include<winsock2.h>
#pragma comment(lib, "ws2_32.lib")
#define PORT 6060
#define BUFFER_SIZE 100
SOCKET gListen, gAccept;
SOCKADDR_IN gAddress;
CHAR buffer[BUFFER_SIZE] = { 0 };
// 서버
int main()
{
// 윈속 초기화
WSADATA wsaData;
if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0)
{
printf("socket() failed with error %d\n", WSAGetLastError());
return -1;
}
if ((gListen = socket(AF_INET, SOCK_STREAM, 0)) == INVALID_SOCKET)
{
printf("socket() failed with error %d\n", WSAGetLastError());
return -1;
}
gAddress.sin_family = AF_INET;
gAddress.sin_addr.s_addr = INADDR_ANY;
gAddress.sin_port = htons(PORT);
// 소켓 바인딩
if (bind(gListen, (PSOCKADDR)&gAddress, sizeof(gAddress)) == SOCKET_ERROR)
{
printf("bind() failed with error %d\n", WSAGetLastError());
return -1;
}
// 연결 요청 수신 대기
if (listen(gListen, 5))
{
printf("listen() failed with error %d\n", WSAGetLastError());
return -1;
}
std::cout << "Waiting for a connection..." << std::endl;
// 연결 수락
if ((gAccept = accept(gListen, NULL, NULL)) == INVALID_SOCKET)
{
printf("accept() failed with error %d\n", WSAGetLastError());
return -1;
}
std::cout << "Connection!" << std::endl;
// 받기
if (recv(gAccept, buffer, sizeof(buffer), 0) <= 0)
{
printf("WSARecv() failed with error %d\n", WSAGetLastError());
return -1;
}
std::cout << "Message received: " << buffer << std::endl;
// 종료
closesocket(gListen);
closesocket(gAccept);
WSACleanup();
return 0;
}
*클라이언트
#include<iostream>
#include<string>
#include<WinSock2.h>
#include <ws2tcpip.h>
#pragma comment(lib, "ws2_32.lib")
#define PORT 6060
#define ADDR "127.0.0.1"
#define BUFFER_SIZE 100
SOCKET gSocket;
SOCKADDR_IN gAddress;
CHAR buffer[BUFFER_SIZE] = {0};
// 클라
int main()
{
Sleep(1000);
// 윈속 초기화
WSADATA wsaData;
if (WSAStartup(MAKEWORD(2, 2), &wsaData) != 0)
{
printf("socket() failed with error %d\n", WSAGetLastError());
return -1;
}
gAddress.sin_family = AF_INET;
gAddress.sin_port = htons(PORT);
if (inet_pton(AF_INET, ADDR, &(gAddress.sin_addr)) != 1)
{
printf("Invalid IP address %d\n", WSAGetLastError());
return -1;
}
else
{
std::cout << "Server IP address: " << ADDR << std::endl;
if ((gSocket = socket(AF_INET, SOCK_STREAM, 0)) == INVALID_SOCKET)
{
printf("socket() failed with error %d\n", WSAGetLastError());
return -1;
}
if (connect(gSocket, (SOCKADDR*)&gAddress, sizeof(gAddress)) < 0)
{
printf("connect() failed with error %d\n", WSAGetLastError());
return -1;
}
std::cout << "Connected to server!" << std::endl;
std::string sendMessage;
std::cout << "Input massge: ";
std::cin >> sendMessage;
/* 5. 메시지 전송 */
send(gSocket, sendMessage.c_str(), sendMessage.length(), 0);
closesocket(gSocket);
}
WSACleanup();
return 0;
}메모리 맵 (Memory Map)
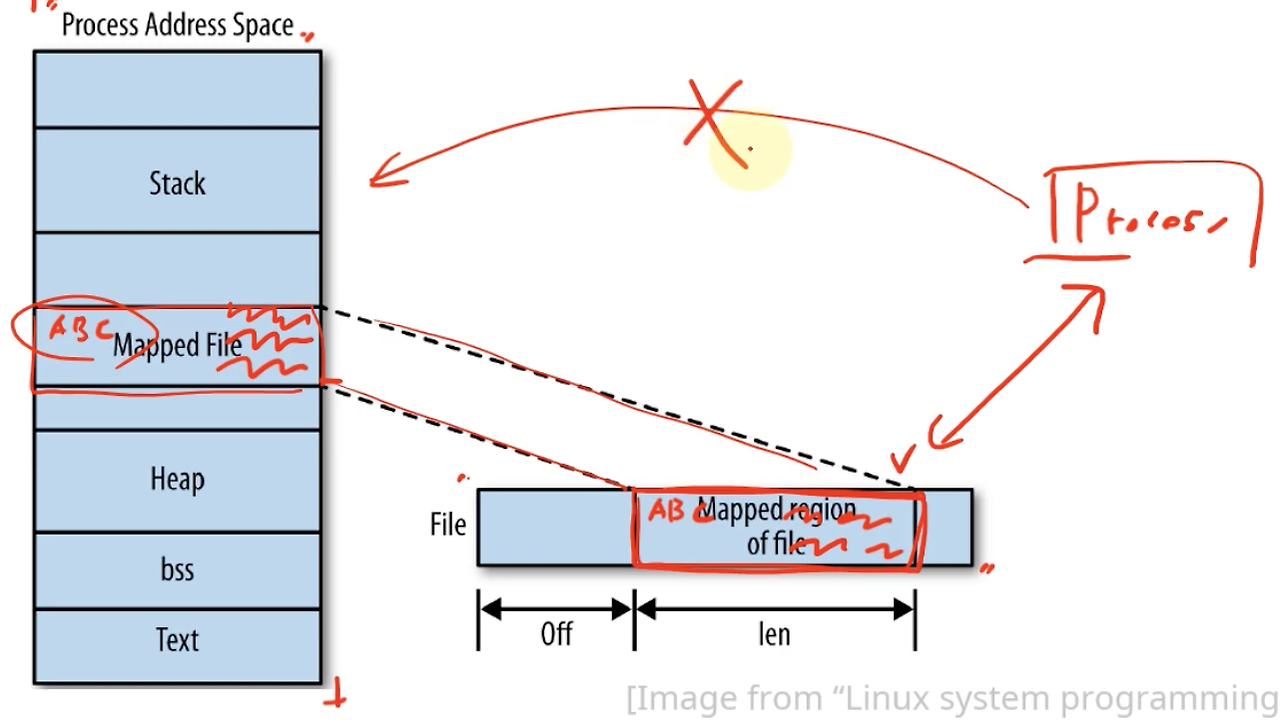
특징
- 파일을 프로세스에 매핑시켜 파일의 메모리에 접근하여 읽거나 쓰는 기법입니다.
- 파일을 매핑할 때 실제 물리 메모리 페이지에 해당 파일 데이터를 로드하고, 이 물리 메모리를 가상 메모리 주소로 매핑합니다.
- 공유 메모리와 비슷하나 다른 점은, OS가 메모리 공간을 할당해주는 것이 아닌, 파일의 메모리를 읽고 쓴다는 것입니다.
장점
- 프로세스가 데이터를 메모리에 복사하는 것이 아닌, 직접 쓰고 읽으므로 속도가 빠릅니다.
- 여러 프로세스가 동일한 데이터를 읽기, 쓰기가 가능합니다.
- 다른 IPC에 비해 비교적 큰 데이터를 처리하기가 간편합니다.
단점
- 데이터의 동기화 문제에 주의해야 합니다.
- 메모리에 직접 접근하므로 보안에 취약할 수 있습니다.
- 할당한 메모리를 해제하지 않으면 메모리 누수가 발생할 수 있습니다.
번외1) 메모리 맵 vs 파일 I/O
파일을 읽고 쓰는거면 파일IO(std::filesystem 등)랑 다른게 뭘까요? 몇몇 차이점이 존재합니다.
1. 메모리 맵은 실제 메모리 공간을 사용하는 기법이나, 파일I/O는 파일의 데이터를 버퍼로 복사하고, 버퍼로 씁니다.
2. 메모리 맵은 파일의 용량에 상관없이 필요한 데이터만 로드하지만, 파일IO는 모든 데이터를 직접 로드하고 쓰기 때문에 느립니다.
번외2) 그러면 수십 기가바이트의 파일을 어떻게 로드할까?
앞서, 메모리 맵은 파일의 용량에 상관없이 필요한 데이터만 로드한다고 했는데요. 어떤 식으로 그렇게 로드할 수 있는걸까요?
간단합니다! 필요한 데이터가 있는 페이지만 로드하게 됩니다. 때문에 파일의 용량이 아무리 커도 속도에 영향을 받지 않습니다.
사용법
CreateFileMappingA 함수(winbase.h) - Win32 apps | Microsoft Learn
CreateFileMappingA 함수(winbase.h) - Win32 apps
지정된 파일에 대한 명명되거나 명명되지 않은 파일 매핑 개체를 만들거나 엽니다. (CreateFileMappingA)
learn.microsoft.com
MapViewOfFile 함수(memoryapi.h) - Win32 apps | Microsoft Learn
MapViewOfFile 함수(memoryapi.h) - Win32 apps
호출 프로세스의 주소 공간에 파일 매핑 보기를 매핑합니다.
learn.microsoft.com
메모리 맵 사용 예시
#include <iostream>
#include <windows.h>
#define FILE_PATH "example.txt"
#define BUFFER_SIZE 256
int main() {
// 파일 열기(없으면 생성)
HANDLE hFile = CreateFileA(
FILE_PATH, // 파일 경로
GENERIC_READ | GENERIC_WRITE, // 읽기/쓰기 권한
0, // 공유 모드 없음
NULL, // 보안 속성
OPEN_ALWAYS, // 파일이 없으면 생성
FILE_ATTRIBUTE_NORMAL, // 일반 파일 속성
NULL // 템플릿 파일 없음
);
if (hFile == INVALID_HANDLE_VALUE) {
std::cerr << "CreateFile failed: " << GetLastError() << std::endl;
return -1;
}
// 파일 매핑 생성
HANDLE hMapFile = CreateFileMappingA(
hFile, // 파일 핸들
NULL, // 보안 속성
PAGE_READWRITE, // 읽기/쓰기 권한
0, // 파일 크기 상위 32비트
BUFFER_SIZE, // 파일 크기 하위 32비트
NULL // 이름 없음
);
if (hMapFile == NULL) {
std::cerr << "CreateFileMapping failed: " << GetLastError() << std::endl;
CloseHandle(hFile);
return -1;
}
// 매핑된 메모리 접근
LPVOID pBuf = MapViewOfFile(
hMapFile, // 메모리 매핑 핸들
FILE_MAP_ALL_ACCESS, // 접근 권한
0, // 오프셋 상위 32비트
0, // 오프셋 하위 32비트
BUFFER_SIZE // 매핑 크기
);
if (pBuf == NULL) {
std::cerr << "MapViewOfFile failed: " << GetLastError() << std::endl;
CloseHandle(hMapFile);
CloseHandle(hFile);
return -1;
}
// 데이터 쓰기
strcpy_s((char*)pBuf, BUFFER_SIZE, "Hello, File Mapping!");
std::cout << "Data written to file via mapping: " << (char*)pBuf << std::endl;
// 메모리 해제
UnmapViewOfFile(pBuf);
CloseHandle(hMapFile);
CloseHandle(hFile);
return 0;
}
'프로그래밍 > CS' 카테고리의 다른 글
| [CS] 페이지 교체 알고리즘 (0) | 2024.11.25 |
|---|---|
| [CS] 데드락(Deadlock) (0) | 2024.11.25 |
| [CS] 뮤텍스(Mutex)와 세마포어(Semaphore) (2) | 2024.11.19 |
| [CS] MMU, TLB (0) | 2024.11.04 |
| [CS] 세그멘테이션 (0) | 2024.11.04 |