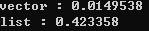
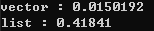
안녕하세요구르트
이번 포스팅은 [CS] 프로세스와 스레드 :: #공부중 (tistory.com)에서 아주 간략하게 다룬 PCB와 Context Switching에 대해 좀 더 자세히 다뤄보겠습니다.
PCB란 무엇인가
PCB(Process Control Block)는 프로세스가 생성될 때 운영체제에 의해 생성되는 것으로, 생성된 프로세스에 대한 메타데이터를 저장하고 있습니다. PCB는 프로세스의 중요한 정보를 포함하고 있기 때문에 유저 영역에서 접근하지 못하도록 커널 스택의 가장 앞부분에서 관리됩니다.

●PCB의 구조
- 프로세스 식별자 (PID: Process ID)
각 프로세스를 유일하게 구분하기 위한 고유 식별자입니다. - 프로세스 상태 (Process State)
프로세스가 현재 어떤 상태에 있는지 나타냅니다. 프로세스는 다음과 같은 상태 중 하나에 있을 수 있습니다:- New: 프로세스가 생성되었지만 아직 실행되지 않음.
- Running: 프로세스가 CPU에서 실행 중임.
- Waiting (Blocked): 프로세스가 어떤 이벤트(입출력 등)를 기다리는 중임.
- Ready: 프로세스가 실행 준비 상태이며, CPU를 사용할 수 있기를 기다리는 중임.
- Terminated: 프로세스가 실행을 마치고 종료된 상태임.
- 프로그램 카운터 (Program Counter)
다음에 실행할 명령어의 주소를 저장합니다. 문맥 교환이 발생할 때 이 값을 이용해 이전 프로세스의 상태를 복구할 수 있습니다. - CPU 레지스터 상태
문맥 교환을 할 때, CPU 레지스터의 내용을 저장하고 복구하는 데 사용됩니다. 이를 통해 중단된 프로세스가 나중에 재개될 때 이전 상태를 유지할 수 있습니다. - 메모리 관리 정보
프로세스의 메모리 공간과 관련된 정보들을 담고 있습니다. 예를 들어, 페이지 테이블, 세그먼트 테이블, 메모리 한계 레지스터 등이 포함될 수 있습니다. - 프로세스 상태 (Process State)
프로세스의 실행 중, 대기 중, 종료 상태 등 프로세스의 현재 상태에 대한 정보입니다. - 계정 정보 (Accounting Information)
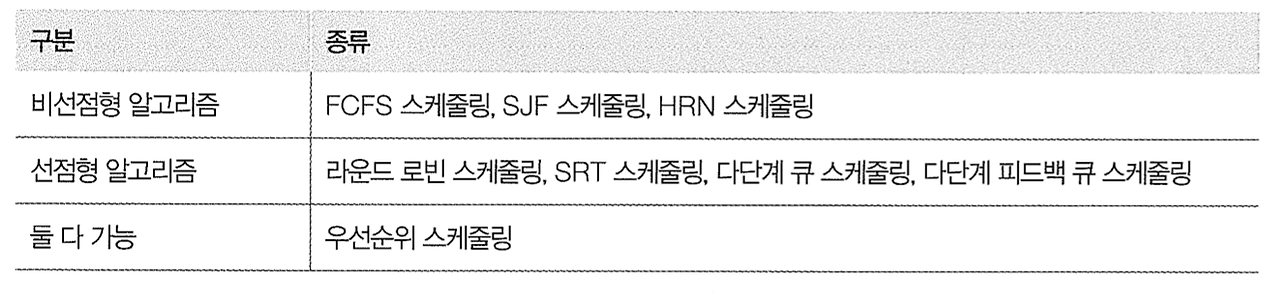
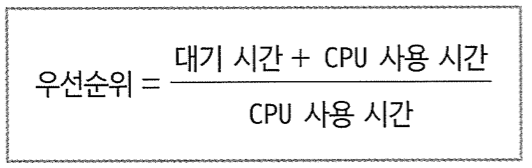
CPU 사용 시간, 프로세스의 우선순위, 실행된 시스템 호출 수 등 프로세스의 성능 및 자원 사용에 관한 정보입니다. - 입출력 상태 정보 (I/O Status Information)
프로세스가 사용하는 입출력 장치, 열려 있는 파일 목록, 입출력 요청 큐 등의 정보를 담고 있습니다.
●PCB의 역할
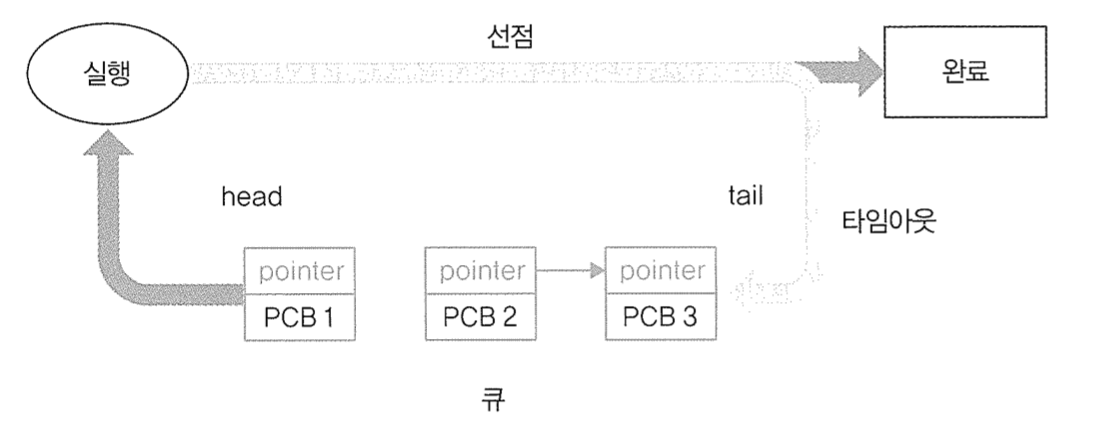
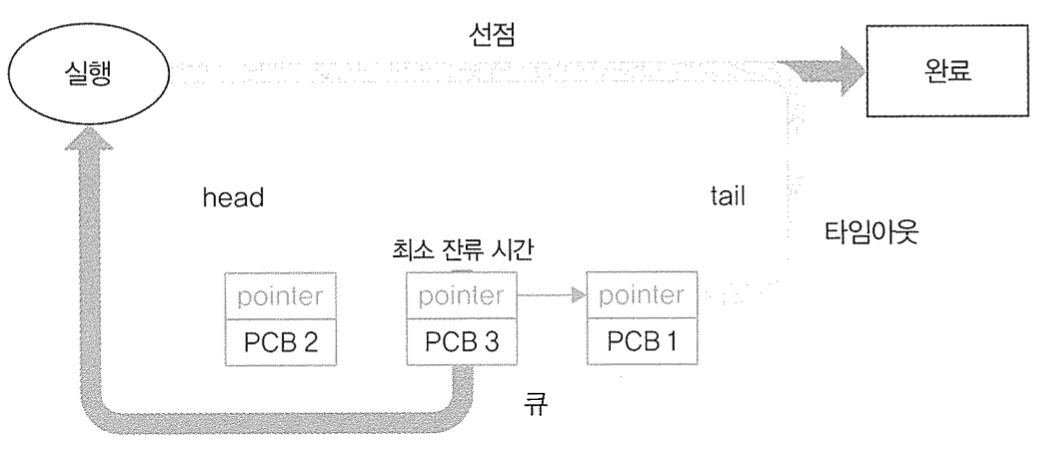
운영체제는 PCB를 사용해서 여러 프로세스를 관리할 수 있습니다. CPU의 각 코어는 여러 프로세스를 동시에 처리할 수 없기 때문에 짧은 시간동안 여러 프로세스를 하나씩 빠르게 처리하게 되는데요, 프로세스의 전환 과정에서 다음 프로세스의 정보를 읽어와야 작업을 진행할 수 있기 떄문에 프로세스의 정보, 즉 PCB를 필요로 합니다.
Context Switching란 무엇인가
컨텍스트 스위칭은 운영체제(OS)에서 현재 실행 중인 작업의 상태(context)를 저장하고, 다른 작업의 상태를 복원하여 실행을 전환하는 과정을 말합니다. 운영체제에서 하는 작업이기 때문에 당연히 커널영역으로의 전환이 이루어집니다.
프로세스나 스레드와의 전환만이 컨텍스트 스위칭이 일어난다고 생각하실 수도 있는데, 뿐만 아니라 여러 상황에서 이루어집니다.
●Context Switching이 일어나는 상황
컨텍스트 스위칭은 여러 상황에서 일어날 수 있습니다. 대표적인 4가지 경우가 있는데요.
- 프로세스 전환: 하나의 프로세스가 실행 중일 때, OS가 다른 프로세스로 전환해야 하면, 현재 프로세스의 상태를 저장하고 다른 프로세스의 상태를 불러와 실행합니다.
- 스레드 전환: 멀티스레드 환경에서, 하나의 스레드에서 다른 스레드로 전환할 때도 컨텍스트 스위칭이 일어납니다.
- 시스템 호출: 프로그램이 시스템 리소스에 접근하기 위해 커널 모드로 전환하는 순간에도 컨텍스트 스위칭이 발생합니다. 이때는 사용자 모드에서 커널 모드로, 다시 커널 모드에서 사용자 모드로 돌아가는 과정에서 전환이 이루어집니다.
- 인터럽트 처리: 외부 장치나 타이머 등에서 인터럽트가 발생하면, 현재 작업의 상태를 저장하고 인터럽트 핸들러로 전환되면서도 컨텍스트 스위칭이 일어날 수 있습니다.
●Context Switching에서 다루는 정보
컨텍스트 스위칭에서 다루는 정보들은 뭐가 있을까요? GPT쌤한테 물어봤습니다.
1. 프로그램 카운터 (Program Counter)
- 역할: 현재 실행 중인 명령어의 위치를 저장.
- 설명: 프로세스 또는 스레드가 멈췄던 지점에서 다시 실행을 재개하려면, 중단된 지점의 명령어 위치를 정확히 알아야 해. 프로그램 카운터는 이 위치 정보를 저장하고 있기 때문에, 이를 복원하여 다음 실행 지점에서부터 이어서 실행할 수 있어.
2. CPU 레지스터 (CPU Registers)
- 역할: 연산 중인 데이터와 결과 값을 저장.
- 설명: 프로세스나 스레드가 작업 중에 CPU 레지스터에는 여러 변수 값이나 중간 계산 결과가 담겨 있어. 컨텍스트 스위칭 시에 이 레지스터의 값을 저장하고, 전환된 작업의 레지스터 값을 복원하여 이어서 연산을 수행할 수 있도록 해.
3. 스택 포인터 (Stack Pointer) 및 프레임 포인터 (Frame Pointer)
- 역할: 함수 호출의 스택 정보와 지역 변수를 관리.
- 설명: 함수 호출 시 함수의 실행 정보를 스택에 쌓고, 함수가 끝나면 스택에서 꺼내는 구조야. 스택 포인터는 현재 스택의 최상단 위치를 가리키고, 프레임 포인터는 특정 함수 호출의 시작 지점을 가리켜. 이 정보가 저장되고 복원됨으로써 함수 호출이 끊김 없이 연결될 수 있어.
4. 메모리 관리 정보 (Memory Management Information)
- 역할: 프로세스의 메모리 맵 및 페이지 테이블 정보를 관리.
- 설명: 프로세스마다 사용하는 메모리 주소 공간이 다르기 때문에, 커널은 프로세스 전환 시 해당 프로세스의 가상 메모리 맵과 페이지 테이블을 관리해. 이를 통해 해당 프로세스가 접근해야 하는 메모리 자원을 올바르게 연결해줄 수 있어.
5. 프로세스 상태 (Process State)
- 역할: 프로세스가 현재 어떤 상태에 있는지를 저장.
- 설명: 프로세스는 실행 상태, 준비 상태, 대기 상태 등 다양한 상태를 가질 수 있어. 이 정보는 커널이 프로세스를 정확한 상태로 전환하고 처리할 수 있도록 해주는 중요한 정보야.
6. 파일 디스크립터 테이블 (File Descriptor Table)
- 역할: 프로세스가 열어둔 파일의 정보와 네트워크 소켓 등을 관리.
- 설명: 프로세스는 실행 중에 파일이나 소켓 같은 리소스를 열어 사용할 수 있어. 이러한 파일 디스크립터 정보는 전환된 프로세스에서도 동일하게 유지되어야 하기 때문에, 커널은 이 정보를 저장하고 복원해.
7. 입출력 상태 (I/O State)
- 역할: 프로세스가 대기 중인 입출력 작업의 상태 정보를 관리.
- 설명: 만약 프로세스가 어떤 입출력 작업(예: 파일 읽기/쓰기, 네트워크 통신 등)을 기다리는 상태라면, 커널은 해당 작업이 어느 단계에 있는지 그 상태를 기록하고 있어. 이를 통해 나중에 다시 프로세스를 복원할 때 그 입출력 작업을 이어서 수행할 수 있게 해.
8. 특권 레벨 (Privilege Level)
- 역할: 프로세스가 사용자 모드인지, 커널 모드인지를 저장.
- 설명: 시스템 호출이나 인터럽트가 발생할 때, CPU는 사용자 모드에서 커널 모드로 전환돼. 이 특권 레벨 정보가 정확하게 유지되어야 올바른 권한으로 작업을 수행할 수 있어.
●각 상황마다의 Context Switching
컨텍스트 스위칭은 작업의 전환이란 큰 틀에선 똑같지만, 상황에 따라 다루는 정보들이 달라집니다.
각각의 상황에서 커널이 어떤 정보를 읽고 저장하는지 알아봅시다.
1. 프로세스 전환 (Process Switching)
- 읽는 정보: 프로세스는 독립된 실행 단위이기 때문에 상태를 완전히 저장하고 복원해야 합니다.
- 프로그램 카운터 (Program Counter): 프로세스가 중단된 위치.
- CPU 레지스터 (CPU Registers): 프로세스에서 사용 중이던 모든 레지스터 값.
- 스택 포인터 (Stack Pointer) 및 프레임 포인터 (Frame Pointer): 프로세스의 함수 호출 및 지역 변수 상태.
- 메모리 관리 정보 (Memory Management Information): 가상 메모리 주소 공간, 페이지 테이블 정보.
- 프로세스 상태 (Process State): 실행 상태, 준비 상태, 대기 상태 등의 현재 상태.
- 파일 디스크립터 테이블 (File Descriptor Table): 프로세스가 열어 둔 파일 및 소켓 정보.
- 입출력 상태 (I/O State): 프로세스가 기다리고 있는 입출력 작업의 상태.
프로세스 전환은 완전히 다른 메모리 주소 공간과 자원을 사용하는 독립적인 작업을 전환하는 것이기 때문에, CPU 레지스터 및 메모리 관련 정보 전부를 저장 및 복원해야 합니다.
2. 스레드 전환 (Thread Switching)
- 읽는 정보: 스레드는 같은 프로세스 내에서 실행되므로 프로세스의 정보는 공유되지만, 스레드 고유의 정보는 저장 및 복원해야 합니다.
- 프로그램 카운터 (Program Counter): 스레드가 중단된 지점.
- CPU 레지스터 (CPU Registers): 스레드에서 사용 중이던 레지스터 값.
- 스택 포인터 (Stack Pointer) 및 프레임 포인터 (Frame Pointer): 스레드의 호출 스택 상태.
스레드는 프로세스 내에서 실행되기 때문에 메모리 관리 정보와 파일 디스크립터 테이블은 공유합니다. 그래서 프로세스 전환보다는 상대적으로 적은 양의 정보를 저장하고 복원하지만, CPU 상태와 스택 정보는 개별적으로 관리해야 합니다.
3. 시스템 호출 (System Call)
- 읽는 정보: 시스템 호출은 사용자 모드에서 커널 모드로 전환될 때 발생하는데, 이때는 사용자 모드에서 커널 모드로 전환하는 정보만 필요합니다.
- 프로그램 카운터 (Program Counter): 사용자 모드에서 커널 모드로 전환되기 직전의 위치.
- CPU 레지스터 (CPU Registers): 현재 사용 중이던 레지스터 값.
- 스택 포인터 (Stack Pointer): 커널 모드에서 사용할 새로운 스택.
- 특권 레벨 (Privilege Level): 사용자 모드에서 커널 모드로 전환하는 권한 정보.
시스템 호출은 같은 프로세스 내에서 일어나는 일이기 때문에, 메모리 관리 정보나 파일 디스크립터는 변경되지 않고 그대로 유지됩니다. 사용자 모드에서 커널 모드로 전환되기 위한 최소한의 상태 정보만 저장하고 복원합니다.
4. 인터럽트 처리 (Interrupt Handling)
- 읽는 정보: 인터럽트는 외부 사건에 의해 발생하며, 현재 작업을 잠깐 중단하고 인터럽트 처리 루틴으로 전환하는 것이기 때문에 비교적 적은 정보를 저장합니다.
- 프로그램 카운터 (Program Counter): 인터럽트 발생 시점의 명령어 위치.
- CPU 레지스터 (CPU Registers): 작업 중이던 레지스터 값.
- 특권 레벨 (Privilege Level): 인터럽트가 발생할 때, 커널 모드로의 전환 여부.
인터럽트는 매우 짧은 시간 동안 실행되기 때문에 메모리 관리 정보나 입출력 상태는 그대로 유지되고, 필요한 정보만 빠르게 저장하고 원래 작업으로 복원합니다.
'프로그래밍 > CS' 카테고리의 다른 글
| [CS] 물리 메모리와 가상 메모리 (0) | 2024.11.04 |
|---|---|
| [CS] 페이징(Paging) (0) | 2024.10.22 |
| [CS] 인터럽트 (0) | 2024.10.22 |
| [CS] CPU 스케줄링 (4) | 2024.10.21 |
| [CS] CPU의 메모리 계층 구조 (4) | 2024.10.13 |