ㅎㅇ헬로봉주르
이번 포스팅은 CPU의 메모리 계층 구조에 관해 작성해볼까 합니다.
특히 캐시와 레지스터라는 용어는 개발자의 입장에선 정말 많이 접하게 되는데요.
그만큼 중요한 개념이고, 알게 많기 때문에 글이 길어질듯 합니다.
같이 알아봅시다 ㄱㄱ싱
CPU의 메모리 계층 구조는 어떻게 생겼을까?
CPU의 메모리는 계층 구조로 이루어져 있습니다.
어떻게 생겼을까요?

(이미지 참고 : [CS/운영체제] 메모리 계층 구조도, 그리고 캐시 메모리(Cache memory) (velog.io))
[CS/운영체제] 메모리 계층 구조도, 그리고 캐시 메모리(Cache memory)
메모리 계층은 아래와 같은 구성 요소로 이루어져 있습니다. 메모리 계층 구조(Memory hierarchy)란 메모리를 필요에 따라 여러 가지 종류로 나누어 둠을 의미합니다. 그 이유는 메모리를 필요에 따
velog.io
바로 이렇게 생겼습니다.
메인 메모리는 주 기억장치, 혹은 저희가 친숙하게 부르는 RAM이라고도 부릅니다.
하드 디스크는 보조 기억장치라고도 부릅니다.
사진에서의 핵심 포인트가 있습니다. 한 번 알아볼까요?
1. 처리속도와 저장용량이 반비례한다.
사진을 자세히 보시면 레지스터>캐시(L1, L2, L3)>주 기억장치(RAM)>보조 기억장치(HDD)순으로 속도가 빠르다고 나와있는데요. 이는 CPU와의 물리적 거리가 해당 순서대로 가깝기 때문입니다.또한 고속 메모리를 만들기 위한 설계와 비용적 제약으로 인해 처리속도와 저장용량이 반비례하게 됩니다.
2. 휘발성 메모리와, 비휘발성 메모리로 나뉜다.
레지스터, 캐시, RAM은 휘발성 메모리, HDD는 비휘발성 메모리입니다.
여기서 휘발성 메모리와 비휘발성 메모리는 데이터 유지 특성에 따라 구분하는데요.
- 휘발성 메모리 : 전원이 공급될 때만 데이터를 유지하는 메모리입니다. CPU에 접근해 빠른 속도로 데이터를 읽고 쓰기가 가능해 작업 중인 데이터를 임시로 저장하는 용도로 사용합니다.
- 비휘발성 메모리 : 전원이 꺼져도 데이터를 유지하는 메모리입니다. CPU에 직접 접근할 수 없고 커널(파일 시스템)을 통해 RAM에 로드하기 때문에 속도가 느립니다. 주로 영구 저장용 메모리로 사용됩니다.
이런 특징들로 인해 각자의 역할이 나뉘어져 있습니다. 하나씩 차근차근 알아보겠습니다.
레지스터(Register)
레지스터는 CPU에서 가장 가까운 위치에 있는 메모리입니다.
1. 레지스터의 특징
레지스터의 주요 특징을 살펴보겠습니다.
- CPU가 연산 등의 요청을 처리하는데 필요한 데이터를 일시적으로 저장합니다.
- 속도가 매우 빠릅니다. (CPU와 가장 가까운 메모리이기 때문)
- 휘발성 메모리입니다.
- 용량이 매우 작습니다.
2. 레지스터가 데이터를 읽고 쓰는 과정
사실 로우레벨 프로그래밍을 하지 않으면 접할 일이 거의 없을겁니다.
굳이 볼 수 있긴한데, 디버그 중 VS의 디스어셈블리 창을 열어보시면 해당 사진과 비슷한 광경이 나옵니다.
그 전에 먼저, CPU에는 산술연산장치(ALU)라고 CPU로부터 들어온 연산요청을 처리하는 장치가 있습니다.
해당 연산에 사용할 데이터를 주로 레지스터에서 꺼내오게 되는데요. 연산을 수행한 후, 결과를 다시 레지스터나 RAM에 저장하게 됩니다.
해당 코드를 순서대로 설명해보자면,
1. mov dword ptr [a], 2 (변수 a에 값 2를 저장합니다. (a의 주소는 현재 스택 프레임에 위치합니다.)
2. mov dword ptr [b], 3 (변수 b에 값 3을 저장합니다.)
3. mov eax, dword ptr [b] (b의 값을 eax 레지스터에 로드합니다.)
4. mov ecx, dword ptr [a] (a의 값을 ecx 레지스터에 로드합니다.)
5. add ecx, eax (eax(b의 값)와 ecx(a의 값)를 더하여 ecx에 저장합니다.(이 때, ALU를 통해 연산을 거치게 됩니다))
6. mov eax, ecx (결과를 eax 레지스터에 저장합니다.)
7. mov dword ptr [c], eax (c 변수에 eax의 값을 저장합니다.)
이로써 c는 a + b의 결과값이 됩니다.
캐시(Cache)
캐시는 CPU 내부에 위치하는 레지스터와 RAM의 중간 사이의 메모리입니다.
1. 캐시의 특징
캐시의 주요 특징을 살펴보겠습니다.
- 자주 사용하는 데이터를 캐시에 저장하여 메인 메모리(RAM)와의 접근 시간을 줄입니다.(병목현상 ↓)
- 레지스터보다는 느리지만, RAM보다는 훨신 빠릅니다.
- 휘발성 메모리입니다.
- L1, L2, L3 캐시로 계층이 나뉘어 있으며, L1이 상대적으로 가장 빠르지만 용량이 적고, L3가 상대적으로 가장 느리지만 용량이 큽니다.
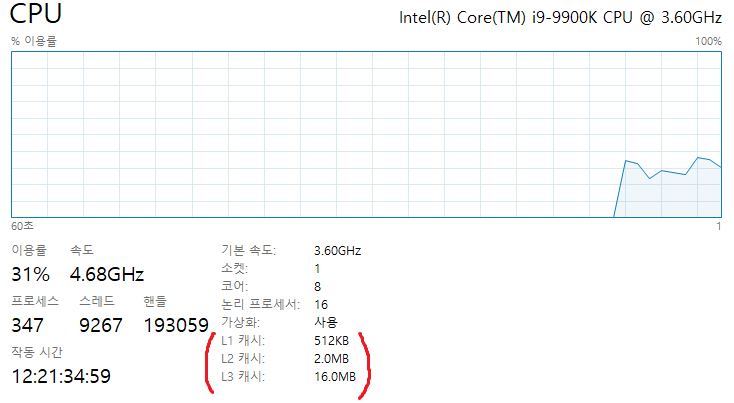
2. 캐시의 역할
캐시는 레지스터와 RAM의 속도 차이에서 발생하는 병목현상을 줄이기 위해 만들어진 메모리입니다.
캐시는 자주 사용되는 데이터나 명령어를 저장하여 CPU가 메모리에 접근할 필요를 줄입니다. CPU가 특정 데이터를 여러 번 참조할 때, 해당 데이터가 캐시에 존재하면 RAM보다 훨씬 빠르게 접근할 수 있습니다.
캐시는 내부적으로 구현되어있는 캐시 관리 정책과 구조에 따라 자주쓰는 데이터를 효율적으로 적재하여 CPU가 데이터를 읽을 때 캐시에 있는 데이터를 먼저 탐색하여 쓰게됩니다.
3. 캐시 데이터 쓰이는 과정
캐시의 동작 과정을 알아보기 전에 알아가야 할 두 키워드가 있습니다.
●캐시 미스와 캐시 히트
- 캐시 미스 : CPU가 특정 데이터를 사용하려고 할 때, 먼저 캐시를 확인합니다. 이때 캐시에 사용할 데이터가 없을 경우 캐시 미스라고 합니다.
- 캐시 히트 : CPU가 특정 데이터를 사용려고 캐시를 확인한 결과, 캐시에 사용할 데이터가 있는 경우 캐시 히트라고 합니다.
(캐시 미스와 캐시 히트는 정말 많이 접하게 되는 용어니까 알아두면 좋습니다.)
그럼 캐시의 데이터는 어떤식으로 쓰일까요?
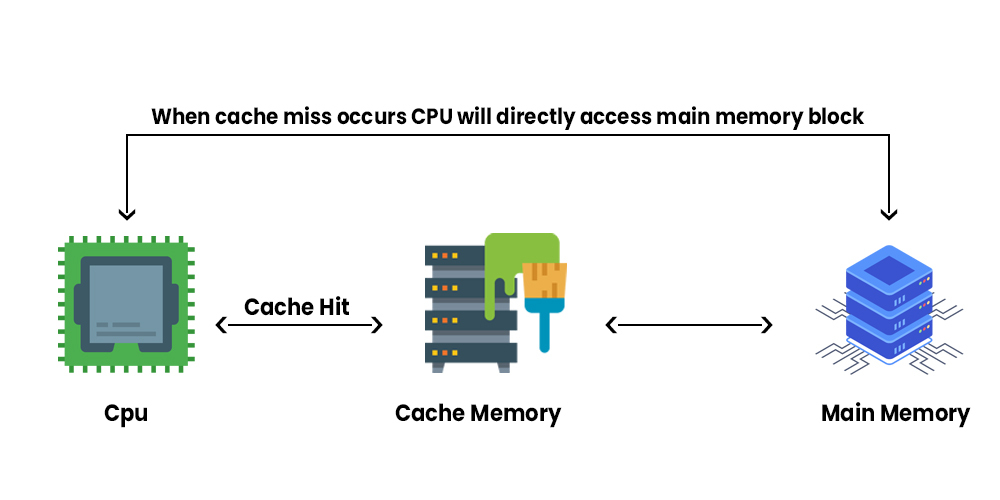
캐시의 데이터는 CPU가 RAM에 접근하는 과정에서 자동으로 관리됩니다.
CPU가 특정 데이터를 사용하려고 할 때, L1 → L2 → L3순으로 캐시를 확인하게 됩니다.
이 때, 캐시에 데이터가 없는 경우(캐시 미스), 캐시에 데이터가 있는 경우(캐시 히트)로 총 두 가지로 나눌 수 있는데요.
1. 캐시 미스가 발생한 경우 : 캐시에 데이터가 없을 경우 RAM에 접근하여 데이터를 가져와 캐시에 저장하고, 이 데이터를 사용하여 연산을 수행합니다.
2. 캐시 히트가 발생한 경우 : 캐시에 데이터가 있을 경우 CPU는 RAM에 접근하지 않고 캐시에서 바로 해당 데이터를 가져와 연산을 수행합니다.
4. 캐시가 쌓이는 과정
캐시가 어떤 방식으로 쓰이는지를 봤는데요, 반대로 캐시가 쌓이는 과정도 알아봅시다.
캐시는 제한된 크기에서 데이터를 효율적으로 쌓고, 교체하기 위해 다양한 캐시 알고리즘을 통해 데이터를 관리합니다.
캐시 교체 알고리즘은 무엇이 있을까요?
1. LRU (Least Recently Used)
LRU는 메모리에 남아있는 캐시 중 가장 오랫동안 사용되지 않은 데이터를 교체하는 알고리즘입니다. 오랫동안 사용하지 않았던 데이터는 앞으로도 사용할 확률이 적다고 판단하기 때문입니다.
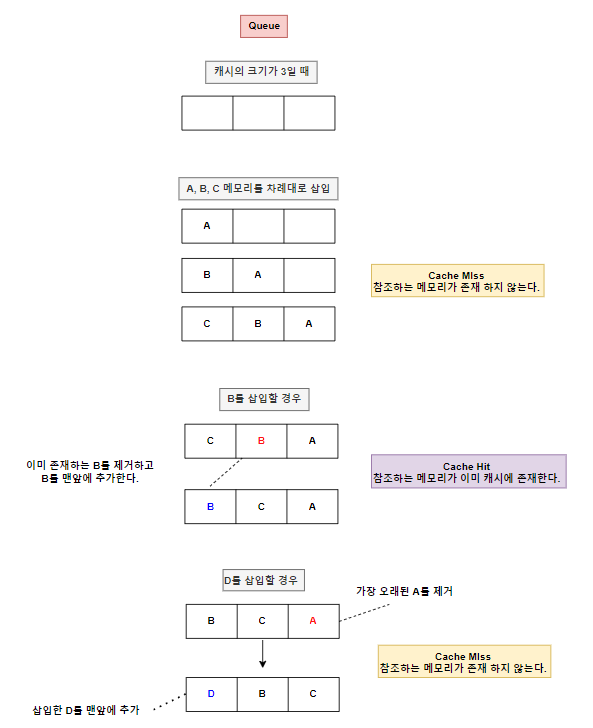
많은 운영체제가 이 방식을 쓰고 있다고 합니다.
2. LFU (Least Frequently Used)
LFU는 메모리에 남아있는 캐시 중 가장 적게 사용되고 있는, 즉 참조 횟수가 가장 적은 데이터를 교체하는 알고리즘입니다. 참조 횟수를 알아야 하므로 각 캐시마다 카운터가 필요합니다.
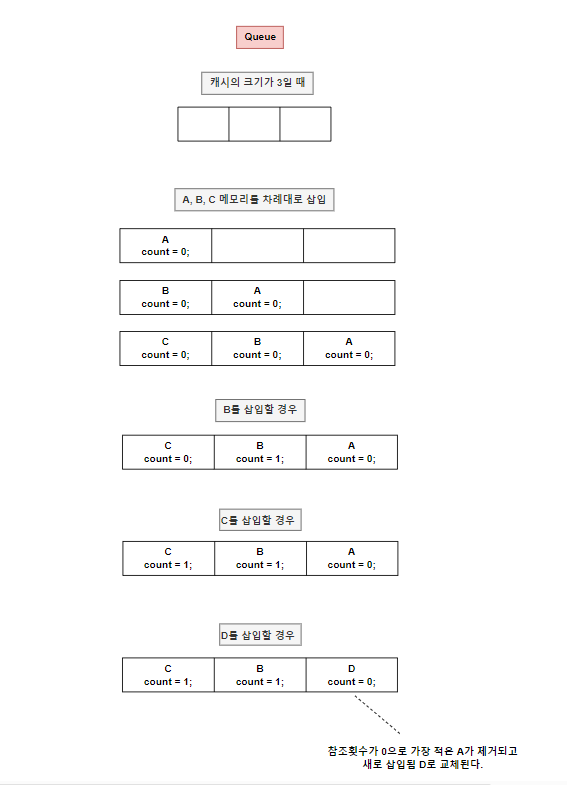
3. FIFO (First In, First Out)
FIFO는 캐시가 꽉 찼을 때, 먼저 들어온 데이터가 먼저 교체 되는 선입선출 구조의 알고리즘입니다.
설명만큼이나 구현도 쉽고 복잡하지 않습니다.
++ 가장 좋은 알고리즘이란??
사실 어느 상황에나 가장 좋고 빠른 알고리즘이란건 없다고 생각합니다. 그럴거면 여러 알고리즘이 존재하지 않았겠죠?
어떤 캐시가 일을 더 잘합니까? — FIFO가 LRU보다 낫습니다요 | by scalalang2 | 취미로 논문 읽는 그룹 | Medium
해당 사이트는 많은 캐시 알고리즘들을 성능 비교분석한 글입니다. 읽어보면 좋을 것 같습니다.
5. 캐시 적중률을 높이는 방법
캐시 히트가 일어나는 비율을 캐시 적중률(or 캐시 히트율)이라고 합니다. 캐시 적중률을 높이는 것은 CPU가 RAM에 접근하는 빈도가 줄어드는 것이므로 성능향상을 꾀할 수 있습니다.
때문에 캐시 메모리의 이점을 제대로 활용하려면 CPU가 사용할 법한 데이터를 예측해서 코드를 짜는 것이 바람직합니다.
CPU가 사용할 법한 데이터를 어떻게 예측하려면 CPU의 메모리 접근 원리를 알아야 하는데요?
CPU의 메모리 접근 원리를 참조 지역성의 원리라고 합니다.
●참조 지역성의 원리
참조 지역성의 원리는 캐시 적중률에 있어서 핵심 개념입니다.
공간적으로나 시간적으로 데이터가 가깝게 사용될 경우 캐시 적중률이 높아질 수 있습니다.
1. 시간 지역성
자주 사용하는 데이터를 반복적으로 접근하는 경우 캐시 적중률이 높아집니다.
CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있기 때문입니다.
시간 지역성을 극대화하기 위해선 루프문 내에 같은 변수를 여러 번 사용하는 구조가 이상적입니다.
2. 공간 지역성
데이터가 캐시 데이터들의 메모리 공간에서 가까운 경우 캐시 적중률이 높아집니다.
CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있기 때문입니다.
공간 지역성을 극대화하기 위해선 배열이나 구조체같은 연속적인 메모리를 통해, 인접한 데이터를 접근하도록 설계하는 구조가 인상적입니다.
++ 캐시 적중률의 중요함(std::vector vs std::list)
벡터와 리스트의 차이는 연속적인 메모리냐 아니냐의 차이입니다.
벡터는 연속적인 메모리의 배열이기 때문에 캐시 적중률이 높습니다.
둘의 순회 시간차이가 얼마나 날까요?
구현 코드)
#define COUNT 10000000
double Process1(std::vector<int>& vec)
{
auto start = std::chrono::steady_clock::now();
for (auto o : vec)
{
++o;
}
auto end = std::chrono::steady_clock::now();
std::chrono::duration<double> elapsed_seconds = end - start;
return elapsed_seconds.count();
}
double Process2(std::list<int>& list)
{
auto start = std::chrono::steady_clock::now();
for (auto o : list)
{
++o;
}
auto end = std::chrono::steady_clock::now();
std::chrono::duration<double> elapsed_seconds = end - start;
return elapsed_seconds.count();
}
int main()
{
std::vector<int> vec;
std::list<int> list;
for (int i = 0; i < COUNT; i++)
{
vec.push_back(i);
list.push_back(i);
}
std::cout << "vector : " << Process1(vec) << '\n';
std::cout << "list : " << Process2(list) << '\n';
}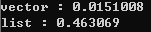
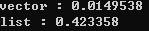
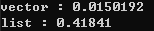
(막상 해보니까 차이가 너무 많이나는데...머지...)
어쨋든 차이가 심합니다. 캐시 적중률을 높이는 것은 개발자에 있어서 숙명이라고 할 수 있겠습니다.
6. 캐시 일관성
CPU는 각기마다 개별 캐시 메모리를 소유하고 있습니다.
때문에 멀티코어 시스템 환경에선 각 코어가 캐시를 사용하는 동안, 서로 동일한 메모리 주소에 대한 데이터가 일관되게 유지되도록 해야합니다. 이를 캐시 일관성이라고 하는데요.
어떤 상황에서 캐시 일관성 문제가 발생할까요?
CPU1과 CPU2가 있다고 가정해봅시다.
- CPU1은 메모리 주소 X에 저장된 값을 자신의 캐시에 저장했습니다.
- CPU2도 메모리 주소 X에 저장된 값을 자신의 캐시에 저장했습니다.
- CPU1이 캐시에서 값을 읽어와 변경하고, 메모리에 쓰지 않았습니다.
- CPU1이 캐시에서 값을 변경한 후 메모리에 쓰지 않았기 때문에 CPU2는 여전히 이전 값을 자신의 캐시에 유지하게 됩니다.
- 이 경우 CPU1과 CPU2는 동일한 메모리 주소 X에 대한 서로 다른 값을 가지게 됩니다.
이러한 문제가 발생할 시 데이터 무결성에 문제가 생깁니다.
이를 방지하기 위해 캐시 일관성 프로토콜이 사용된다는데요? 나중에 알아봅시다.
메인 메모리(RAM)
프로세스의 주소공간에 할당되는 메모리는 메인 메모리에 해당됩니다.
1. 메인 메모리의 특징
메인 메모리의 주요 특징에 대해 살펴보겠습니다.
- 프로그램이 실행 중일 때 필요한 데이터와 명령어를 임시로 저장합니다.
- CPU에게 처리할 데이터를 전달해줍니다.
- 레지스터, 캐시보단 속도가 느리지만, HDD보다 빠릅니다.
- 휘발성 메모리입니다.
- HDD에 비해 상대적으로 작은 용량을 가지고 있습니다. (통상 8~32GB)
2. RAM과 HDD의 관계
RAM은 HDD의 데이터를 로드해 CPU가 빠르게 데이터를 처리할 수 있도록 도와줍니다. RAM이 부족할 경우, 가상 메모리나 페이지 파일을 통해 HDD를 메모리처럼 사용할 수 있습니다.
예를 들자면, 운영체제나 프로그램을 실행할 때, HDD에서 RAM으로 데이터를 로드하여 프로그램이 원할하게 실행되도록 해줍니다.
하드 디스크(HDD, SSD)
메모리 계층 구조에서 CPU가 데이터를 접근하는 데 가장 느린 장치입니다.
1. 하드 디스크의 특징
하드 디스크의 주요 특징에 대해 살펴보겠습니다.
- 장기적인 데이터 저장을 위해 사용합니다.
- 속도가 느립니다.
- 비휘발성 메모리입니다.
- 대용량 저장이 가능합니다.
2. HDD vs SSD
HDD와 SSD는 다들 들어보셨을겁니다.
용량은 HDD가 SSD보다 많지만, 속도는 SSD가 훨 빠르다는 사실을 대부분 아실겁니다. 그 이유가 뭘까요?
1. HDD와 SSD의 구조적 차이
HDD : 데이터를 읽고 쓰기 위해서 기계적인 부품(플래터)와 읽기/쓰기 헤드를 사용합니다. 데이터를 읽거나 쓰기 위해서는 플래터가 특정 위치로 회전해야 하고, 읽기/쓰기 헤드가 해당 위치로 이동해야 합니다. 이 과정에서 데이터 접근 시간이 길어집니다. 또한 데이터를 병렬적으로 처리하지 못하기 때문에 동시에 여러 데이터에 접근하기 어렵습니다.
SSD : 데이터를 전자적으로 처리하는 플래시 메모리 칩을 사용하여 데이터를 읽고 씁니다. 기계적 부품이 없기 때문에 데이터에 접근하는 속도가 매우 빠릅니다. 또한 내부에서 병렬 처리가 가능하기 때문에 여러 데이터에 빠르게 접근할 수 있습니다.
'프로그래밍 > CS' 카테고리의 다른 글
| [CS] 인터럽트 (0) | 2024.10.22 |
|---|---|
| [CS] CPU 스케줄링 (4) | 2024.10.21 |
| [CS] 커널(Kernel)과 그 종류에 대해 (0) | 2024.10.13 |
| [CS] 유저영역, 커널영역 그리고 SystemCall (1) | 2024.10.13 |
| [CS] 프로세스와 스레드 (2) | 2024.10.06 |