안녕하세요?
오늘은 뮤텍스와 세마포어에 관해 포스팅을 해보겠습니다!
바로 ㄱㄱ싱
참고자료
Mutex vs Semaphore - GeeksforGeeks
Priority Inversion & Priority Inheritance (우선순위 역전과 우선순위 상속)
동기화 문제
현대 CPU는 거의 멀티 코어를 지원하기 때문에 멀티스레딩을 필수적으로 해야하는데요.
멀티스레딩 기법을 쓰면 데이터의 무결성을 침해하게 되는 경우가 빈번하게 있습니다.
예를 들자면, 스레드A가 특정 자원을 읽는 도중에, 스레드B가 해당 자원을 수정하는 상황이 있습니다.
이 때, 스레드A가 읽는 자원은 경쟁 상태(Race Condition)이 되어 데이터의 무결성을 보장받을 수 없습니다. 이러한 상황을 동기화 문제라고 하는데요.
이러한 상황을 해결하기 위해 동일 자원에 대해서 동기화 문제가 발생할 가능성이 있어 하나의 스레드만 접근할 수 있도록 보호해줘야 되는 영역을 임계영역(Critical Section)이라고 합니다.
임계영역의 구현은 여러가지지만, 오늘은 대표적으로 뮤텍스와 세마포어에 대해 알아보겠습니다. 가보시죠 ㅇㅅㅇ
뮤텍스(Mutex)

뮤텍스는 상호 배제 (mutual exclusion)의 줄임말이며, 한 자원에 대하여 하나의 스레드만 접근할 수 있도록 보호해주는 객체입니다.
뮤텍스는 락킹(Locking)을 통해 오직 하나의 스레드만 임계영역에 들어올 수 있습니다. 락킹은 다음과 같은 연산이 있습니다.
- 락(lock): 현재 스레드가 임계 구역에 들어가기 위해 뮤텍스를 획득합니다. 만일 다른 프로세스나 스레드가 임계 구역을 사용 중이라면 뮤텍스가 해제될 때까지 대기합니다.
- 언락(unlock): 현재 스레드가 임계 구역의 사용이 끝났음을 알리기 위해 뮤텍스를 해제합니다. 이후 다른 스레드가 lock을 통해 임계 구역에 진입할 수 있습니다. 뮤텍스를 소유한 스레드만 해제할 수 있습니다.
● 특징
뮤텍스는 우선순위 역전 문제를 피하기 최소화하기 위하여 우선순위 상속 메커니즘(priority inheritance mechanism)을 사용할 수 있습니다. 뮤텍스는 현재 우선순위가 더 높은 태스크가 가능한 한 가장 짧은 시간 동안 블로킹(blocking) 상태에 있을 수 있도록 합니다. 우선순위 역전 문제를 완전히 해결할 수는 없지만, 그 영향을 줄일 수 있습니다.
● 장점
- 경쟁 상태(Race Condition) 방지: 한 번에 하나의 프로세스만 임계영역에 접근하므로 동기화 문제가 발생하지 않습니다.
- 데이터 무결성 유지: 공유 자원의 일관성을 보장합니다.
- 간단한 잠금 메커니즘: 임계영역에 진입 시 잠금(Lock)하고, 나올 때 해제(Unlock)합니다.
● 단점
- 기아(Starvation) 문제: 스레드가 임계영역에 진입한 상태에서 슬립 상태가 되거나, 우선순위가 높은 프로세스에 의해 선점되면 다른 스레드가 대기 상태에 빠질 수 있습니다.
- 바쁜 대기(Busy Waiting) 문제: 임계영역 접근 권한을 얻기 위해 기다리는 것이 아니라 확인하기 위해 무한 루프를 돌게 되는데, 이 과정에서 CPU 자원이 매우 낭비된다. (그래서 mutex lock을 spinlock이라고 부르기도 한다네요?)
- 잠금 및 해제 메커니즘의 제한: 이전 스레드가 임계영역을 나가기 전까지 다른 프로세스는 접근할 수 없습니다. 즉, 별도의 잠금/해제 방식을 제공하지 않습니다.
● 직접 써보자
직접 써봐야 더 이해가 잘 될거같아서 해보았읍니다.
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
std::vector<int> q;
std::mutex mtx;
// 이 매크로를 끄면 뮤텍스를 안씁니다.
#define USE_MUTEX
void UseMutexWorker(int id)
{
mtx.lock(); // 뮤텍스 획득
// TODO : 작업 실시
q.push_back(id);
std::cout << "Thread ID " << id << " - push_back()\n";
// 작업 종료
mtx.unlock(); // 뮤텍스 해제
}
void DefaultWorker(int id)
{
q.push_back(id);
std::cout << "Thread ID " << id << " - push_back()\n";
}
int main()
{
std::vector<std::thread> workers;
for (int i = 0; i < 10; ++i)
{
#ifdef USE_MUTEX
workers.push_back(std::thread(UseMutexWorker, i));
#else
workers.push_back(std::thread(DefaultWorker, i));
#endif // USE_MUTEX
}
for (int i = 0; i < workers.size(); ++i)
{
// 스레드가 종료되었는가?
workers[i].join();
}
for (int i = 0; i < q.size(); ++i)
{
std::cout << "Queue[" << i << "] = " << "Thread ID " << q[i] << " Visit\n";
}
}스레드에게 ID값을 0~9까지 만들고, 각 스레드들은 전역변수의 큐에 자신의 ID값을 넣는 간단한 코드입니다.
변화를 보기 위해 #define USE_MUTEX 을 사용해 뮤텍스를 쓰는 코드와 안쓰는 코드를 스레드에게 넘겨줬습니다.
1. 뮤텍스를 안쓴 경우
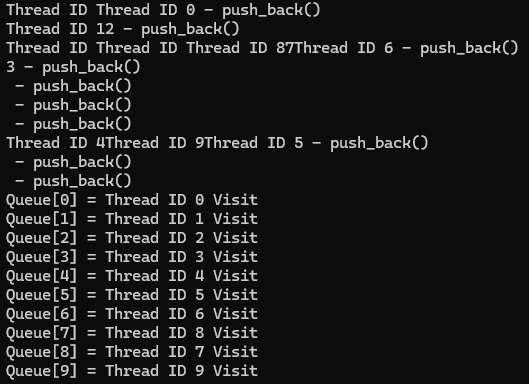
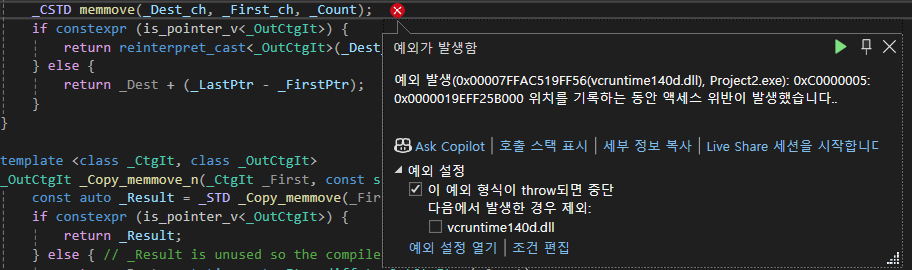
뮤텍스를 쓰지 않으면 큐에 넣는 작업의 순서도 뒤죽박죽이며, 간헐적으로 크래시가 난다. 동시 접근에 대한 에러로 인해 나는 크래시인듯 하다.
2. 뮤텍스를 쓴 경우
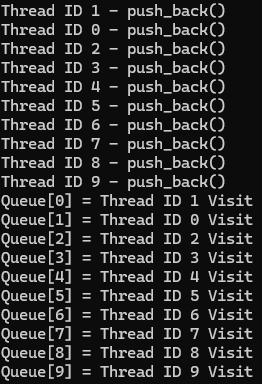
뮤텍스를 쓰면 깔끔해지는 모습이다. 근데 사실 이러면 싱글스레드를 쓴거나 다름없다. 오히려 싱글스레드보다 느리다.
세마포어(Semaphore)
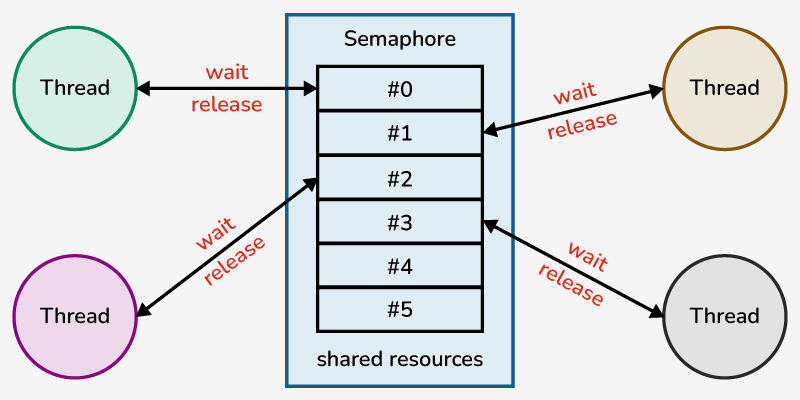
세마포어(Semaphore)는 여러 스레드간에 공유되는 카운터 값인 0이상의 정수형 변수로 이루어진 객체입니다.
여기서
세마포어는 신호형 메커니즘을 기반으로 동작하며, 한 스레드가 다른 스레드에게 신호를 보내는 방식으로 동작합니다.
세마포어는 신호를 주고받아 스레드의 자원 사용을 허용합니다. 신호를 주고받는 연산은 다음과 같습니다.
- wait(): 세마포어의 카운터 값을 감소시키고, 값이 0이 되면 해당 스레드는 대기 상태가 됩니다.
- signal(): 세마포어의 값을 증가시키고, 대기 중인 스레드가 있으면 실행 상태로 전환합니다.
● 특징
세마포어는 뮤텍스와 다르게 하나의 스레드에만 임계영역의 접근 권한을 제한하지 않습니다. 또한 특정 스레드가 반드시 lock과 unlock을 해야하는 엄격한 소유권(Strict Ownership)이 없습니다.
● 장점
- 다중 스레드 접근 허용: 여러 스레드가 동시에 임계영역에 접근할 수 있습니다.
- 기계 독립성: Semaphore는 특정 하드웨어에 종속되지 않으므로 다양한 환경에서 사용 가능합니다.
- 유연한 자원 관리: 제한된 수의 리소스를 효율적으로 관리할 수 있습니다.
● 단점
- 우선순위 역전(Priority Inversion) 문제: 낮은 우선순위의 스레드가 자원을 점유하고 있을 경우, 높은 우선순위의 스레드가 대기 상태에 빠질 수 있습니다.
- 프로그래밍 오류: wait() 및 signal() 호출 순서가 이상해지면 데드락이나 상호 배제 속성 위반이 발생할 가능성이 높습니다.
- 운영 체제의 부하: 운영 체제가 모든 wait() 및 signal() 호출을 추적하고 관리(커널 콜)해야 하므로 부하가 증가할 수 있습니다.
- 바쁜 대기(Busy Waiting) 문제: 임계영역 접근 권한을 얻기 위해 기다리는 것이 아니라 확인하기 위해 무한 루프를 돌게 되는데, 이 과정에서 CPU 자원이 매우 낭비된다.
● 직접 써보자
직접 써봐야 더 이해가 잘 될거같아서 해보았읍니다.
#include <iostream>
#include <windows.h>
#include <thread>
#include <vector>
#define MAX_WORK 3 // 동시에 실행할 수 있는 최대 스레드 수
#define TOTAL_TASKS 10 // 작업 총 개수
std::vector<int> q;
HANDLE semaphore; // 세마포어 핸들
// 이 매크로를 끄면 세마포어를 안씁니다.
//#define USE_SEMAPHORE
void UseSemaphoreWorker(int id)
{
// 세마포어 대기 (카운트가 0이면 대기 상태)
WaitForSingleObject(semaphore, INFINITE);
// 작업 시작
q.push_back(id);
std::cout << "Thread ID " << id << " - push_back()\n";
// 세마포어 해제 (카운트 증가)
ReleaseSemaphore(semaphore, 1, NULL);
}
void DefaultWorker(int id)
{
q.push_back(id);
std::cout << "Thread ID " << id << " - push_back()\n";
}
int main()
{
// 세마포어 생성
semaphore = CreateSemaphore(
NULL, // 보안 속성
MAX_WORK, // 초기 카운트
MAX_WORK, // 최대 카운트
NULL // 세마포어 이름 (익명)
);
std::vector<std::thread> workers;
for (int i = 0; i < TOTAL_TASKS; ++i)
{
#ifdef USE_SEMAPHORE
workers.push_back(std::thread(UseSemaphoreWorker, i));
#else
workers.push_back(std::thread(DefaultWorker, i));
#endif // USE_MUTEX
}
// 모든 스레드가 종료될 때까지 대기
for (auto& t : workers) { t.join(); }
for (int i = 0; i < q.size(); ++i)
{
std::cout << "Queue[" << i << "] = " << "Thread ID " << q[i] << " Visit\n";
}
// 세마포어 닫기
CloseHandle(semaphore);
return 0;
}위 뮤텍스 코드와 동작은 같습니다. 다만 세마포어 객체를 만들어 동기화 관리를 한다는 점에서 다릅니다.
위 코드에선 최대 3개의 스레드가 동시에 일할 수 있도록 설정해놓았습니다.
세마포어를 안쓴 경우는 위 뮤텍스 코드랑 다를게 없어서 넘어가겠습니다.
- 세마포어를 쓴 결과
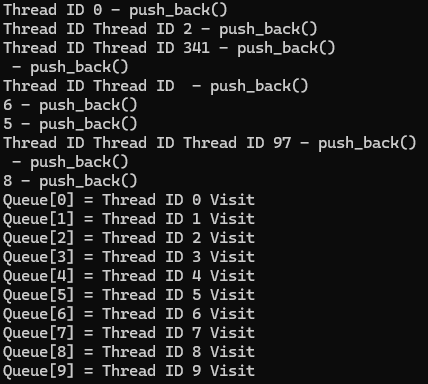
엄 사실 짜고보니까 예시가 세마포어를 써야하는 상황이랑 안맞는 것 같습니다.
어쨋든 동작은 최대 3개의 스레드가 동시에 일하도록 만든 코드입니다...
바쁜 대기(Busy Waiting)이 무조건 나쁠까?
바쁜 대기(Busy Waiting)란?
OS에서는 원하는 자원을 얻기 위해 기다리는 것이 아니라 권한을 얻을 때까지 반복해서 확인하는 것을 의미합니다.
이는 CPU의 자원을 쓸데 없이 낭비하기 때문에 좋지 않은 쓰레드 동기화 방식입니다.
// 예시
while (!flag) {
// 아무것도 안함. 그냥 루프만 돌기
// 혹은 break조건 확인만 하기
}하지만 이를 "무조건 나쁘다"고 단정할 수는 없습니다. 상황에 따라 효율적인 선택이 될 수도 있기 때문입니다.
어째서??
크게 두가지의 이유가 있습니다.
- 컨텍스트 스위칭 비용 회피
- 컨텍스트 스위칭은 운영 체제가 다른 스레드나 프로세스를 실행하기 위해 현재 상태(레지스터, 스택 등)를 저장하고, 새 작업으로 교체하는 작업입니다.
- 이 과정에서 발생하는 **오버헤드(CPU 비용)**는 바쁜 대기보다 클 수 있습니다.
- 짧은 대기 시간이 예상된다면, 컨텍스트 스위칭 없이 바쁜 대기를 사용하는 것이 더 효율적일 수 있습니다.
- 짧은 시간 내에 락 해제가 예상되는 경우
- 락이 곧 해제될 것이 거의 확실한 상황이라면, 바쁜 대기가 오히려 자원을 빠르게 확보할 수 있는 전략이 됩니다.
- 예: 큐가 거의 비어있고, 생산자-소비자 문제에서 잠깐의 대기만 필요한 경우.
- 특정 알고리즘 또는 자원의 경량 동기화가 필요한 경우
- 대규모 락이나 세마포어 같은 무거운 동기화 도구 대신, 간단히 상태를 확인하면서 대기하는 방법이 더 적합한 경우입니다.
- 예: 아직 안배웠지만, 원자적 변수와 std::atomic을 이용한 동기화에서.
Mutex와 Semaphore에 대한 오해
Mutex와 이진 세마포어(Binary Semaphore)는 종종 혼동됩니다. 많은 사람들이 Mutex가 이진 세마포어라고 생각할 수 있지만, 이는 사실이 아닙니다! Mutex와 세마포어는 다른 목적을 가지고 있습니다. 비록 구현 방식이 비슷하기 때문에 이진 세마포어로 불리기도 하지만, Mutex와 세마포어는 용도와 동작 방식에서 차이가 있습니다.
- Mutex는 자원에 대한 접근을 동기화하기 위해 락킹 매커니즘을 사용합니다.
- 하나의 작업(스레드 또는 프로세스)이 Mutex를 획득할 수 있으며, Mutex를 소유한 작업만 잠금을 해제할 수 있습니다.
- Semaphore는 운영 체제에서 신호(Signaling) 메커니즘으로 사용되며, 공유 자원에 대한 접근을 제어합니다.
- 예를 들어, 컴퓨터에서 대용량 파일을 다운로드(Task A)하면서 동시에 문서를 인쇄(Task B)하려고 한다고 가정해봅시다.
- 인쇄 작업이 시작되면 Semaphore는 다운로드가 완료되었는지 확인합니다.
- 다운로드가 진행 중이면, Semaphore는 인쇄 작업을 대기 상태로 만들어 "다운로드가 끝날 때까지 기다려 주세요"라고 신호를 보냅니다.
- 다운로드가 완료되면 Semaphore는 인쇄 작업을 시작하라는 신호를 보냅니다.
- 이처럼 Semaphore는 두 작업이 서로 간섭하지 않도록 하며, 시스템 자원을 효율적으로 관리하여 작업 간 충돌 없이 부드럽게 실행되도록 합니다.
바람직한 동기화 문제 해결
오늘은 뮤텍스와 세마포어를 이용해 동기화 문제를 해결하는 방법을 알아보았습니다.
그럼 동기화 문제가 발생했을 때는 꼭 동기화 객체를 이용해야 동기화 문제를 잘 해결했다고 볼 수 있을까요? 라고 묻는다면 그건 아닙니다.
다음과 같은 이유가 있습니다.
1. 프로그래밍에 있어서 동기화 뮤텍스와 세마포어는 커널 객체기 때문에 시스템 호출을 기본적으로 떠안고 가야됩니다. (성능 오버헤드)
2. Busy Wait가 일어나기 때문에 CPU의 자원 낭비가 이루어집니다.
3. 올바른 방법을 사용하지 않고 오용할 경우 데드락(Deadlock)이 발생해 교착상태에 빠질 수 있습니다.
이 외에도 많지만, 그럼에도 쓰는 이유는 올바르게 사용하기만 하면 데이터 무결성을 보장받을 수 있기 때문입니다.
역설로 가보자면, 데이터 무결성만 보장할 수 있다면 동기화 객체를 사용하지 않아도 된다는 것입니다. 즉, 임계영역이 없게끔 설계하는 것이 중요합니다.
예를 들어보겠습니다.
스레드A, B, C가 있고, 30개의 원소가 담긴 배열이 있습니다.
30개의 원소를각각 1로 초기화를 하고싶은데, 이 작업을 스레드 3개로 나눈다고 합시다.
그럼 굳이 동기화 객체를 사용할 필요가 없이 배열 10칸씩 스레드에게 작업을 맡기면 됩니다.
이러면 각 스레드가 서로의 작업 영역에 침범하지 않으므로 데이터가 무결할 수 있습니다.
'프로그래밍 > CS' 카테고리의 다른 글
| [CS] 페이지 교체 알고리즘 (0) | 2024.11.25 |
|---|---|
| [CS] 데드락(Deadlock) (0) | 2024.11.25 |
| [CS] MMU, TLB (0) | 2024.11.04 |
| [CS] 세그멘테이션 (0) | 2024.11.04 |
| [CS] 물리 메모리와 가상 메모리 (0) | 2024.11.04 |