// 인터페이스 정의 (순수 가상 함수만 가진 클래스)
class IAnimal {
public:
virtual void Speak() = 0; // 순수 가상 함수
virtual ~IAnimal() = default; // 가상 소멸자
};
// 인터페이스 구현 클래스 (Dog과 Cat)
class Dog : public IAnimal {
public:
void Speak() override {
std::cout << "월!" << std::endl;
}
};
class Cat : public IAnimㅁal {
public:
void Speak() override {
std::cout << "냥!" << std::endl;
}
};
// 실행 예제
int main() {
IAnimal* dog = new Dog();
IAnimal* cat = new Cat();
dog->Speak(); // 월!
cat->Speak(); // 냥!
delete dog;
delete cat;
return 0;
}
분명 dog와 cat은 IAnimal타입입니다.
하지만 Speak을 호출한 순간, 다형성에 맞게 원래 생성했던 클래스에 맞는 메서드가 호출되었는데요.
다형성은 서로 다른 객체를 같은 인터페이스로 다룰 수 있게 해주는 개념이에요. C++에서는 이를 위해 가상 함수를 사용하고, 이 가상 함수들은 버추얼 테이블에 저장되어 있어요. 이 덕분에 프로그램 실행 중에 어떤 함수가 호출될지를 동적으로 결정할 수 있게 되죠.
버추얼 테이블의 성능
그럼 버추얼 테이블은 무적 아님? 개사긴데? 마구마구 써주마!!!
절!!! 대!!! 아닙니다요!!!!
버추얼 테이블은 다형성을 구현하는 데 필수적이지만, 성능에 영향을 미칠 수 있어요.
가상 함수를 호출할 때마다 현재 객체 -> 최종 객체를 판정하기 위해 테이블을 참조해야 하므로, 일반 함수 호출보다 약간의 오버헤드가 발생해요. 하지만 쓸 수밖에 없는 상황이 오기도 해서, 남용만 안 하면 이 정도 오버헤드는 감수하고 쓰는 편이긴 합니다.
오늘은 어떻게 그런 식으로 캐스팅이 동작하는지 알아볼 거예요. (대충 지루하고 현학적인 이야기다요)
C++스타일의 cast에는 여러 종류가 있는데요.
오늘은 그중에서 가장 많이 쓰이는 cast은 static_cast와 dynamic_cast에 대해 알아봅시다.
● static_cast
static_cast에 대해 많은 오해를 하고 있는 부분이 있어요.
그건 바로 static_cast는 컴파일 타임에 에러를 검출해 낸다는 것인데요.
근데 써보신 분들은 이런 경험을 겪으신 적이 있을 겁니다.
난 분명 static_cast를 썼고, 컴파일도 제대로 되었는데, 런타임 중에 static_cast에서 터졌어!!
분명 컴파일 타임에 에러를 검출해 준다 했는데... 컴파일이 되었는데 터졌어.... 뭐지... 뭔가 일어나고 있음...
이런 경우를 겪으신 분 계신가요? (전 없긴함)
제대로 알고 써야 합니다!!
static_cast는 컴파일 타임에서 A와 B에 대한 상속 관계에 대한 합리성만 판단합니다.
무슨 말인지 예시를 들어보자면, (대충 지루하고 현학적인 예시)
영희는 철수에게 생일선물을 주려고 한다. 영희는 철수가 닌텐도를 가지고 싶다는 이야기를 들었다.. 하지만 철수가 무슨 기종을 가지고 싶은지 명확히 모른다..... 그래서 영희는 최신 기종인 닌텐도 스위치를 선물하기로 했다! 아뿔싸! 철수가 가지고 싶었던 기종은 닌텐도 DS였다!!!!
이런 상황인 것이에요.
런타임 중에 static_cast가 터졌다는 것은,
닌텐도 DS든, 닌텐도 Wii든, 닌텐도 스위치든 전부 닌텐도라 할 수 있는데요.
영희는 이런 상황에 닌텐도 스위치가 닌텐도라는 합리성만 판단하고 위험하게 닌텐도 스위치를 선물한 겁니다.
코드로 표현하자면 이런 거죠.
class Nintendo {};
class Nintendo_Switch : public Nintendo {};
class Nintendo_DS : public Nintendo {};
// 1. 철수: 아 닌텐도가 가지고 싶다!
Nintendo_DS* ds = new Nintendo_DS();
// 2. 영희: 음... 철수가 닌텐도가 가지고 싶다 했지...
Nintendo* nt = ds; // Nintendo로 업 캐스팅
// 3. 영희: 그럼 최신 기종인 닌텐도 스위치를 선물해야겠다!
Nintendo_Switch* sw = static_cast<Nintendo_Switch*>(nt); // 컴파일러는 허용, 그러나 런타임에서는 잘못된 다운캐스팅
컴파일러 입장에선 Nintendo_Switch* ⇐ Nintendo* 관계가 성립하므로 캐스트 자체는 허용되지만, 실제로 ds는 Nintendo_Switch의 주소를 가리키는 게 아니기 때문에 알 수 없는 동작을 하게 됩니다.(보통은 터짐)
그러면 이런 상황에서 안전하게 확인하는 방법이 뭘까요?
그건 바로 dynamic_cast입니다!
● dynamic_cast
dynamic_cast는 말 그대로 안전한 캐스팅입니다.
RTTI를 통해 하나하나 유효성 검사를 실시하기 때문인데요.
RTTI란? Run-Time Type Information의 약자로, 런타임에서의 객체들의 정보를 뜻합니다.
때문에 dynamic_cast는 캐스팅 시, 해당 객체에 대한 타입과 캐스팅 대상 타입을 상속 트리를 통해 하나하나 검사합니다.
실패할 시 터지지 않고 반환 값을 nullptr을 반환해 실패 여부도 확인할 수 있죠.
그럼 무조건 dynamic_cast 써야겠네? 무적이네?
절!!! 대!!! 아닙니다!!!!
하나하나 검사하는데 빠를 리가 없겠죠?
그래서 dynamic_cast는 속도가 느립니다. 여러분 생각보다 훨씬 느려요.
그저 맞냐 or 아니냐를 따지는 과정이 말로는 간단하지만, 여러 상황에 대한 예외 처리 때문에 생각보다 복잡한 과정이 있다고 하더라구요.
심지어 상속 관계가 복잡하고 깊어질수록 더 느려지겠죠?
그래서 자체 엔진 제작할 때 일화를 들려드리자면,
GetComponent<>() 함수 같은 것들에 dynamic_cast를 썼었는데....
테스트해 보니까 속도가 좀 느리더라구요....
그래서 다음에 만들 엔진엔 타입별 ID를 해싱해서 부여하고, 해시 맵으로 성능향상을 노려볼까 합니다.
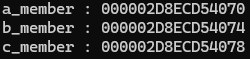
class A { public: int a_member; };
class B { public: int b_member; };
class C : public B, public A { public: int c_member; };
int main()
{
C* c = new C;
A* a = c;
B* b = c;
void* aPtr = static_cast<void*>(a);
void* bPtr = static_cast<void*>(b);
void* cPtr = static_cast<void*>(c);
std::cout << "a: " << aPtr << std::endl;
std::cout << "b: " << bPtr << std::endl;
std::cout << "c: " << cPtr << std::endl;
return 0;
}