[C++] 다중 상속에서의 업캐스팅, 그리고 포인터 보정(1)
오늘 C++에 대한 빨간약을 또 하나 먹었다...
안녕하세요. 저에요.
오늘도 슬프게 코딩을 하던 도중 C++ 빨간약을 먹었는데요?
다중 상속에 대한 것인데, 매우 간과하고 사용하고 있었어요.

C++의 세계란 알아도 끝이 없네요.
함께 알아가보자.
상속의 구조
상속은 컴파일러가 어떤 식으로 처리할까요?
바로 상속 객체 단위로 메모리 레이아웃을 배치하게 되는데요. (알고계셨다구요? 그럼 바로 아래 파트로 넘어가시죠.)

그게 무슨 소리임? 하실까봐 예시 코드를 하나 가져왔습니다.
class A
{
public:
int a_member;
};
class B
{
public:
int b_member;
};
class C : public A, public B
{
public:
int c_member;
};
A와 B를 상속받은 클래스 C가 있다고 칩시다.
그럼 메모리 레이아웃은 어떻게 형성될까요?
바로 C를 만들면서 상속한 순서대로 레이아웃이 형성됩니다.
바로 아래처럼 형성되는데요.

저 같은 놈 말은 안믿는다고요?

그럼 비주얼 스튜디오 메모리 레이아웃을 당장 켜보세요.


그럼 제 말대로 나옵니다. ㅇㅅㅇ
그럼 검증해볼까요?
int main()
{
C* c = new C;
std::cout << "a_member : " << &c->a_member << std::endl;
std::cout << "b_member : " << &c->b_member << std::endl;
std::cout << "c_member : " << &c->c_member << std::endl;
return 0;
}위 예시 클래스를 이용해 main함수를 작성해 보았습니다.
결과는 어떻게 나올까요?
결과:
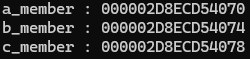
4byte 단위 오프셋이 제대로 적용된 모습입니다.
여담으로, C의 상속 순서를 뒤집으면 어떻게 될까요?

이렇게 상속하면...

이렇게 뜬답니다?
와~~~ 신기하다~~~
지금까지 상속의 구조를 알아봤는데요.

"이게 업캐스팅이랑 뭔 상관임? 내 시간 돌려놓으셈!!!"
다음 파트에서 설명해보겠습니다...
다중 상속에서의 업캐스팅? 알고 쓰자!
위 설명에 사용한 예제에 이어 다음과 같은 코드를 추가해봤습니다.
c를 할당하고, c를 A객체로 업캐스팅한 a와 B객체로 업캐스팅한 b가 있습니다.
class A { public: int a_member; };
class B { public: int b_member; };
class C : public B, public A { public: int c_member; };
int main()
{
C* c = new C;
A* a = c;
B* b = c;
void* aPtr = static_cast<void*>(a);
void* bPtr = static_cast<void*>(b);
void* cPtr = static_cast<void*>(c);
std::cout << "a: " << aPtr << std::endl;
std::cout << "b: " << bPtr << std::endl;
std::cout << "c: " << cPtr << std::endl;
return 0;
}
결과는 어떨까요?
똑같지 않을까요?
결과:

c == a, c != b
충격적이게도 c와 c를 업캐스팅한 a는 같지만 c를 업캐스팅한 b는 다르다...
결과를 보셨나요?

왜 이런 결과가 나왔을까요.
사실 앞서 한 상속의 구조 설명을 잘 읽어보면 답이 있습니다. (괜히 설명한게 아니라고)
c는 사실 사실 가장 첫 상속 객체의 시작 주소를 가리키는데요.
C 클래스는 A->B순서로 상속받았으니 사실상 C에 속한 A 상속 객체의 시작 주소를 가리키고 있는겁니다.
그래서 결과적으로,
c(생성한 원본 C 객체) >> (C 클래스는 C::A의 시작 주소다.)
a(C객체에서 업캐스팅한 A객체) >> (C::A의 시작 주소)
이므로 c == a가 되는 것이고,
b(C객체에서 업캐스팅한 B객체) >> (C::B의 시작 주소 (C의 시작 주소(A)에서 A객체의 메모리 크기만큼 건너 뛴 주소)
이므로 c != a가 되는 것입니다.
따라서 b는 c혹은a의 + 4byte(A객체의 크기)만큼의 주소를 가지게 되는거죠.
사실 이렇게 보면 당연한 소린데, 왜 이런 생각을 안했는지 모르겠네요. 쩝

마치며,
근데 뭔가 이상하지 않나요?
제가 아는 캐스팅은 주소는 안바뀌고, 해당 자료형을 바꿔서 사용하는 줄 알았는데?
c의 주소를 b로 캐스팅하니까 주소가 바뀐거 아닙니까?
그렇다는 것은 캐스팅 메소드가 알아서 주소를 C::B의 오프셋을 적용해서 반환해줬다는 건데.... 이거 괜찮은거 맞음...?
그것에 대해선 다음 포스팅에 다뤄보겠습니다. (이거때문에 (1)이라 적은 것 << 퍽퍽)
어쨋든!
이래서 RAII 설계가 중요하다고 하는 것 같습니다.
객체의 생성을 담당한 주체가 소멸도 담당해야한다는 것이, 이런 문제가 발생할 수도 있으니까 그런 것 같습니다.

이상 저였습니다. 감사합니다.